A Timeline of Large Transformer Models for Speech
Since the arrival of the Transformer architecture in 2017, transformer-based models have made their way into all domains of machine learning. As Andrej Karpathy of Tesla noted, they are quickly becoming the go-to architecture as either a strong baseline or state-of-the-art performance for most problems in language, vision, and now speech.
In speech processing especially, we are seeing many new methods to apply transformers to acoustic data. Popular libraries like HuggingFace’s Transformers are also implementing more and more speech models.
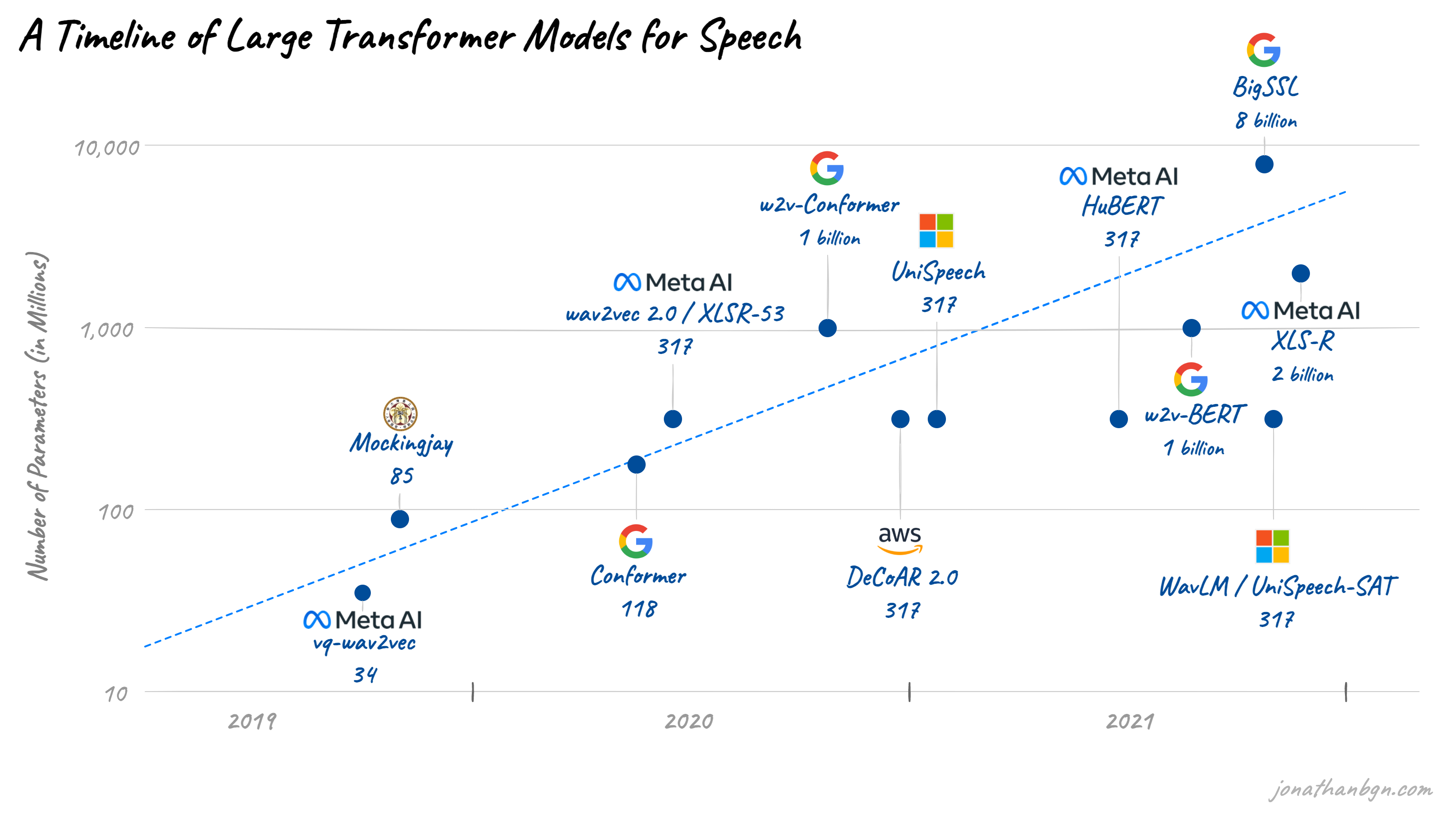
Similar to the natural language processing field, tech companies are now building larger and larger speech transformer models. I will cover some of the most popular ones, starting in 2019 where things started to take off in the speech processing field.
2019: VQ-Wav2vec, Mockingjay, DiscreteBERT
VQ-Wav2vec
The original wav2vec model did not use transformers and instead relied on two distinct convolutional networks. Its immediate successor, vq-wav2vec, re-used the same architecture but applied a quantization process to transform continuous acoustic features into discrete units (VQ stands for Vector Quantization). These discrete representations were then used to train a BERT model, a large transformer encoder network.
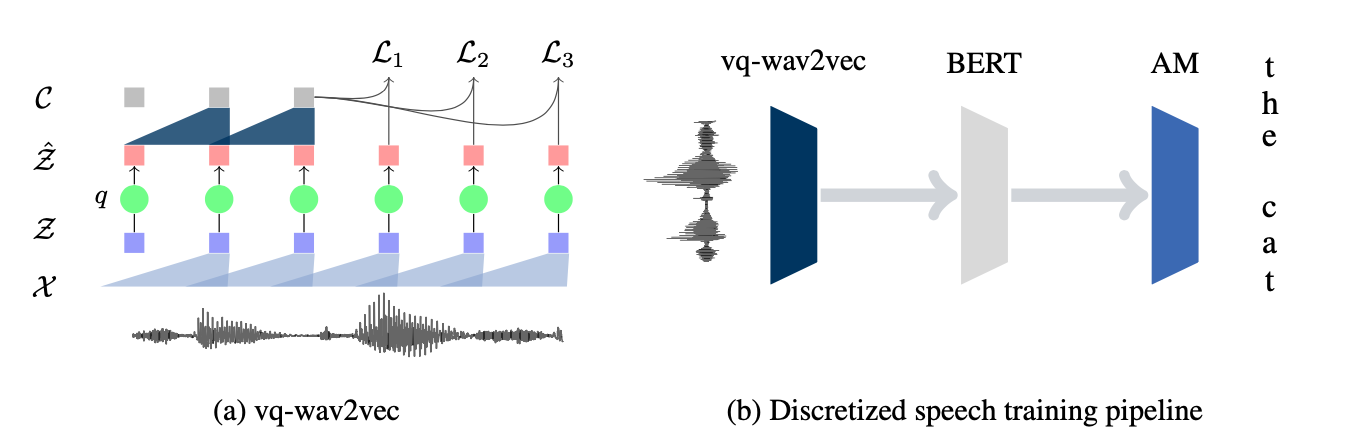
Image from the original vq-wav2vec paper
In contrast to the original BERT model, only the Masked Language Modelling objective was used, as the next sentence prediction objective could hinder performance for speech.
Mockingjay
This model created by researchers at National Taiwan University experimented with applying transformer encoders directly to the continuous audio features, rather than discretizing first like vq-wav2vec. Inspired by BERT, the pre-training process also masks a random subset of audio frames for prediction. However, since the frames were not discretized, the model tries to reconstruct the original features frame, and an L1 reconstruction loss is used as the objective (hence the model is named after a bird that mimics sound).
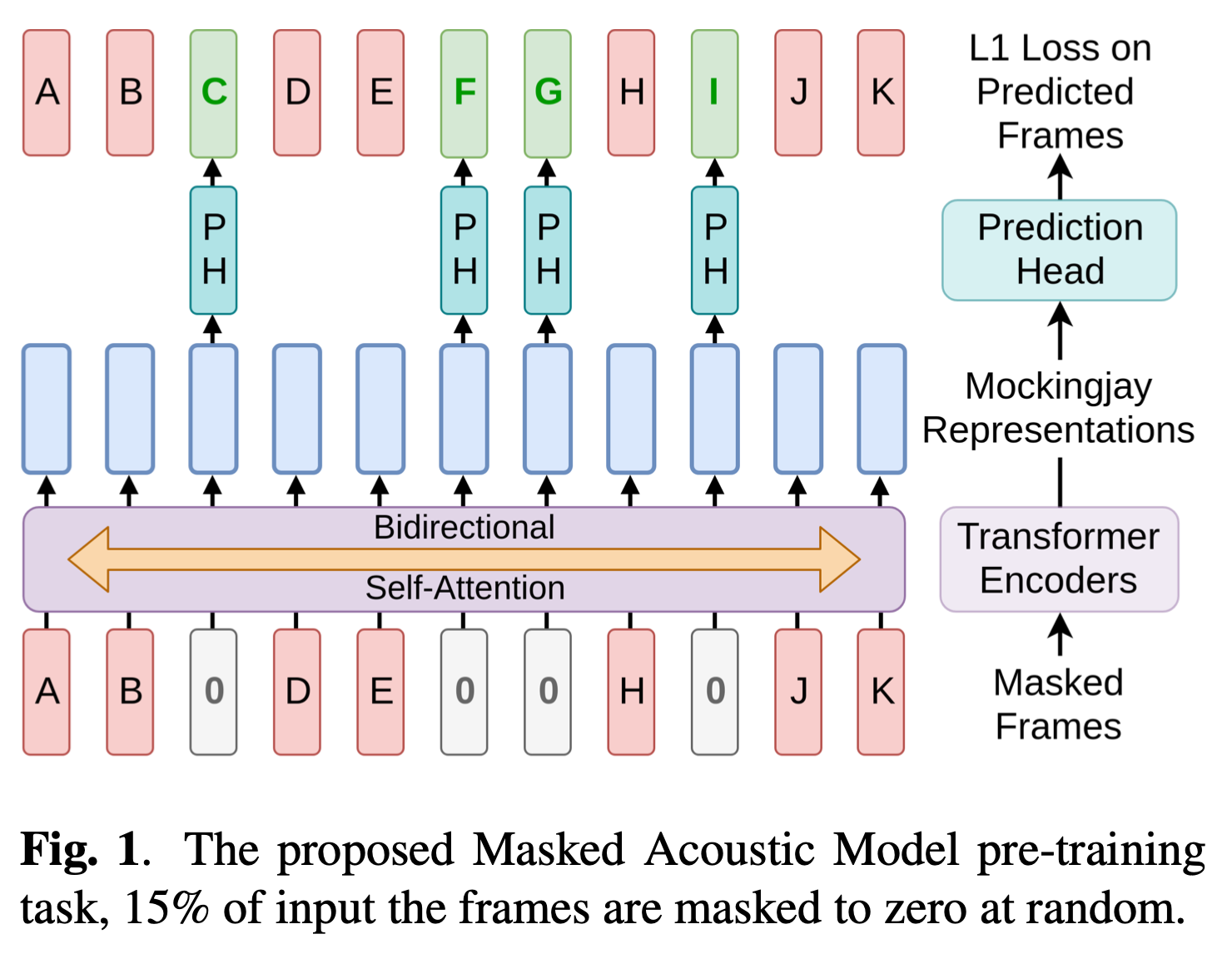
Image from the original Mockingjay paper
The authors report improved performance on a variety of downstream tasks like phoneme classification, speaker recognition, and sentiment classification, after either extracting latent representations from the last layer of the model, a combination of intermediate hidden representations (weighted like ELMo), or directly fine-tuning the model to the downstream tasks.
DiscreteBERT
With the same architecture and training process as vq-wav2vec, DiscreteBERT confirms the benefits of using discrete units as an input for the transformer encoder rather than continuous features. There is some slight difference in the training approach compared to vq-wav2vec, and you can have a look at the paper for more details.
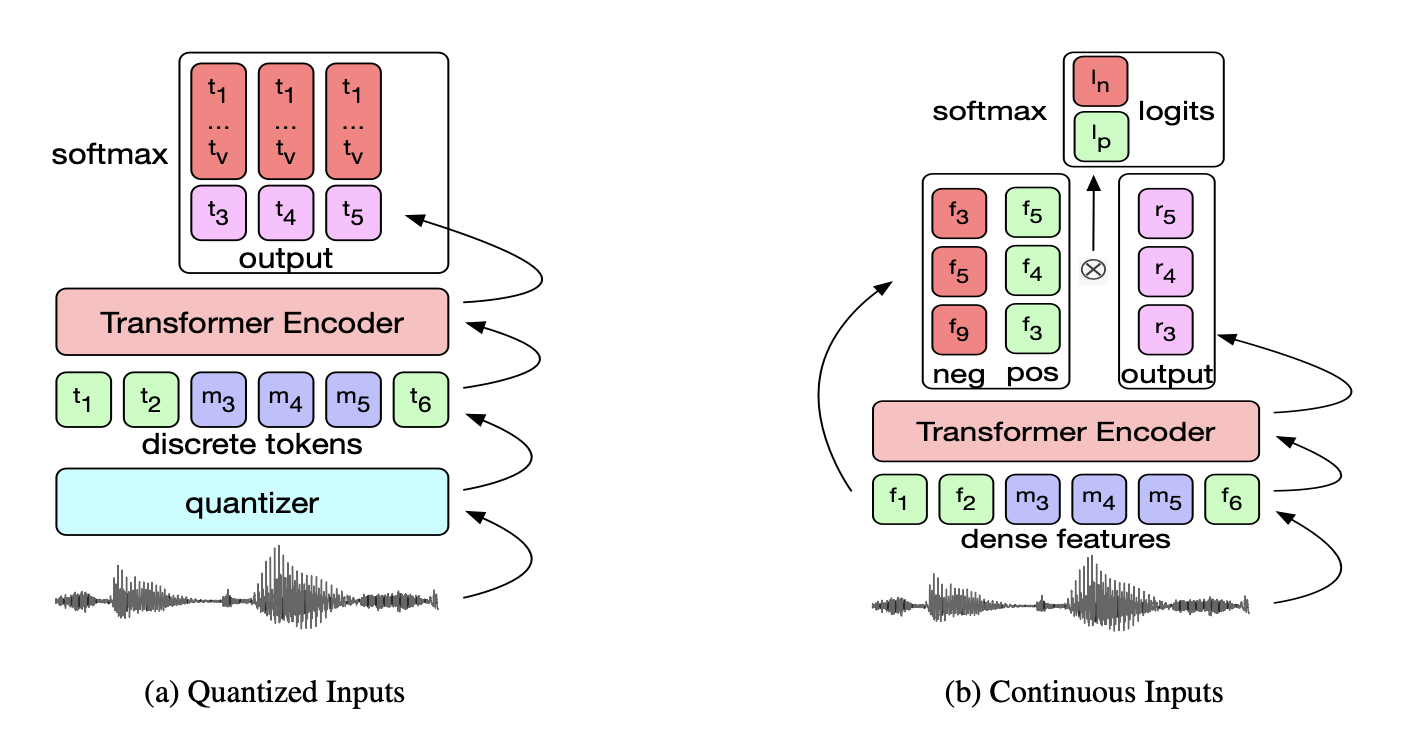
Image from the original paper
2020: Conformer, Wav2vec 2.0, DeCoAR 2.0…
Conformer
In the first half of 2020, researchers at Google combined convolution neural networks to exploit local features with transformers to model the global context and achieved state-of-the-art performance on LibriSpeech. This out-performed previous Transformer-only transducers by a large margin, demonstrating the advantage of combining CNN with Transformer for end-to-end speech recognition. Their architecture replaces the Transformer blocks with Conformer blocks, which add a convolution operation.
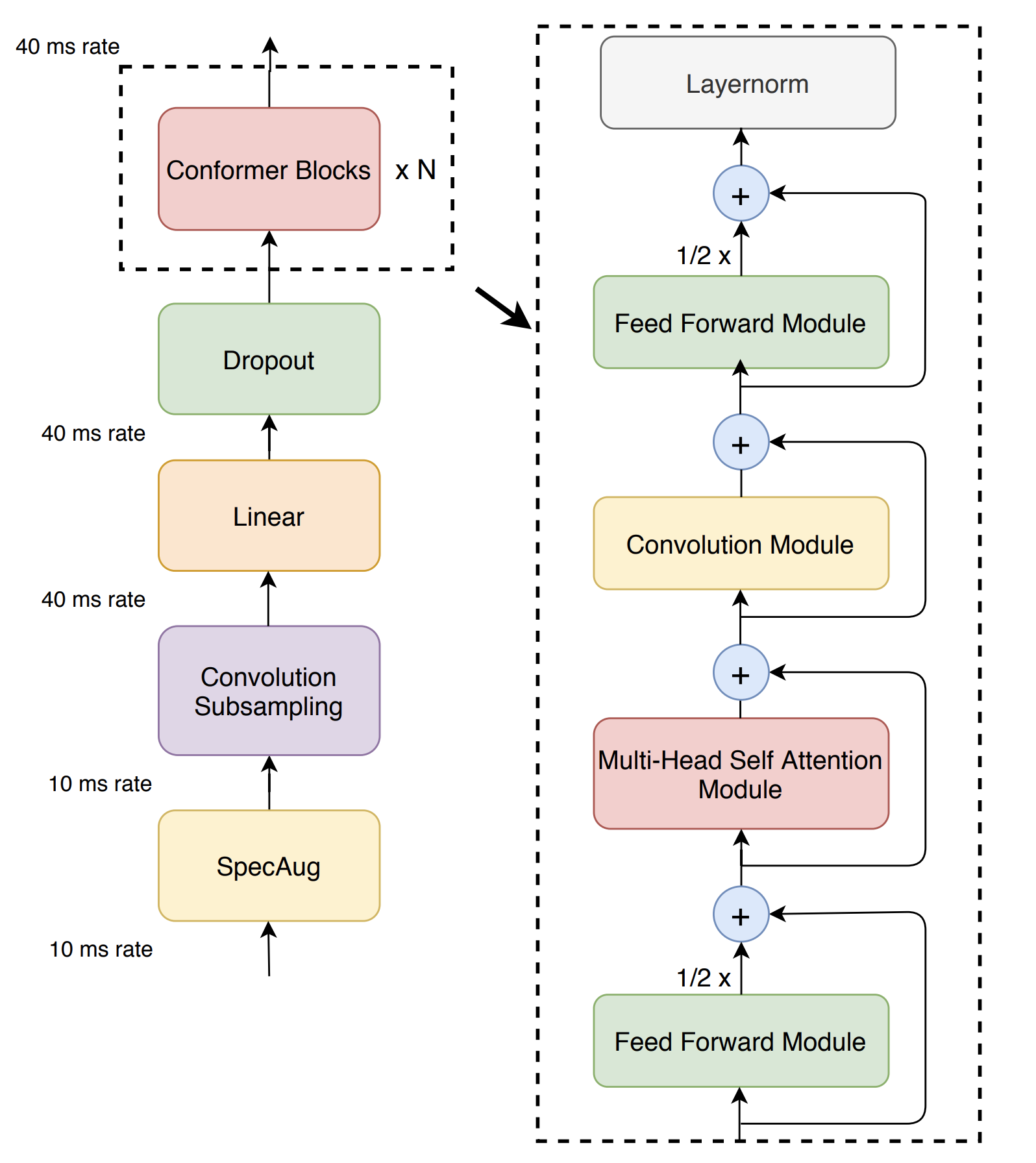
The conformer model combines self-attention with convolution wrapped in two feed-forward modules (Image source)
Wav2vec 2.0 / XLSR-53
A continuation of the wav2vec series, wav2vec 2.0 replaces the convolutional context network of the original architecture with a transformer encoder. Despite the use of discrete speech units and a quantization module like the vq-wav2vec model, wav2vec 2.0 goes back to the original contrastive objective used in the first version of wav2vec, rather than the BERT’s masked language modeling objective.
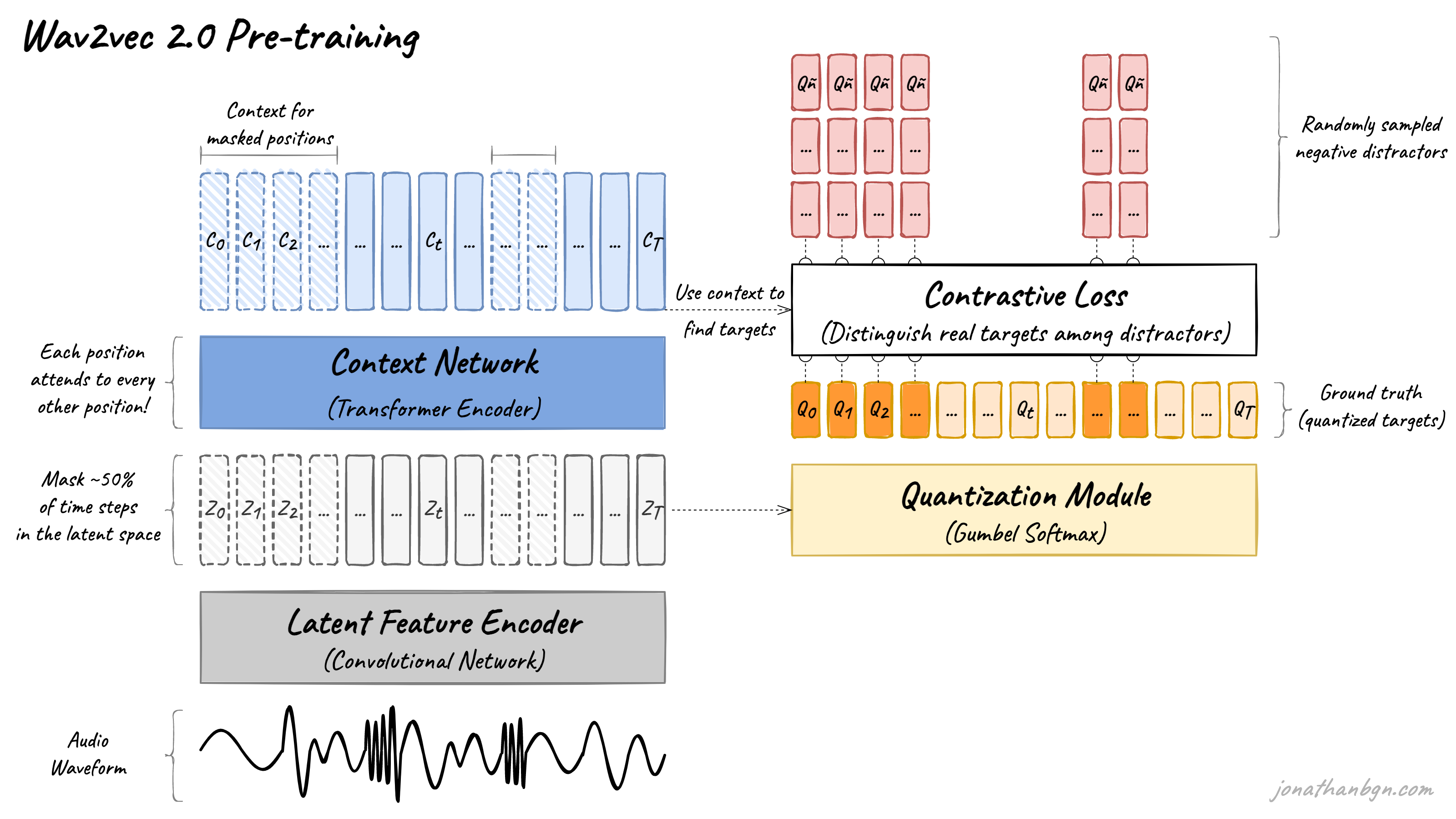
Image from An Illustrated Tour of Wav2vec 2.0
A few days after releasing the wav2vec 2.0 preprint, Facebook AI also released XLSR-53, a multi-lingual version of the wav2vec 2.0 model trained in 53 languages.
w2v-Conformer
In a preprint released in October 2020, a team at Google merged the Conformer architecture with the wav2vec 2.0 pre-training objective and noisy student training to reach new state-of-the-art results on LibriSpeech speech recognition. The team also scaled the model to a much larger dimension than the original wav2vec 2.0 paper, with a Conformer XXL model using 1 billion parameters.
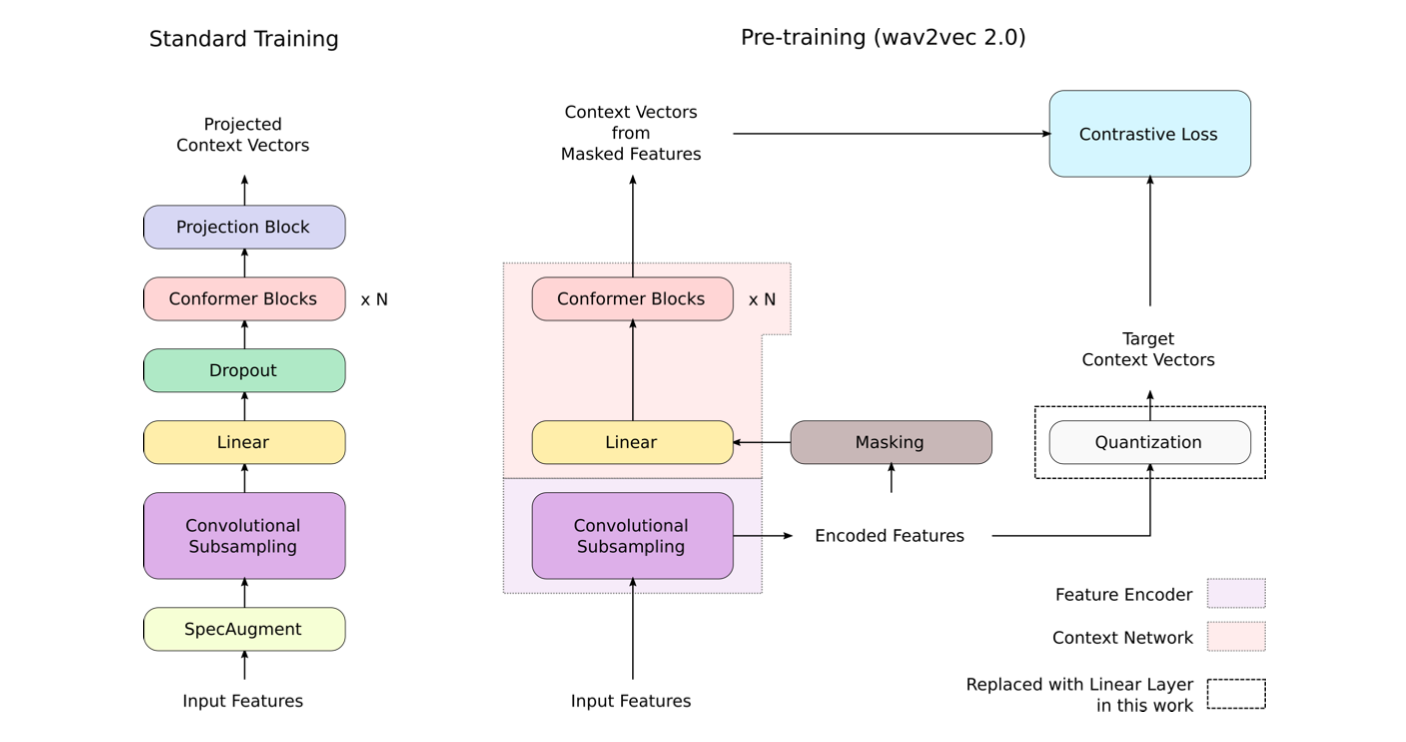
Image from the original paper
DeCoAR 2.0
This model from Amazon Web Services is the successor of a non-transformer LSTM-based model named DeCoAR (Deep Contextualized Acoustic Representations), which takes its inspiration directly from the popular ELMo model in natural language processing. This second version replaces the bi-directional LSTM layers with a transformer encoder and uses a combination of the wav2vec 2.0 loss and another reconstruction loss as its objective.
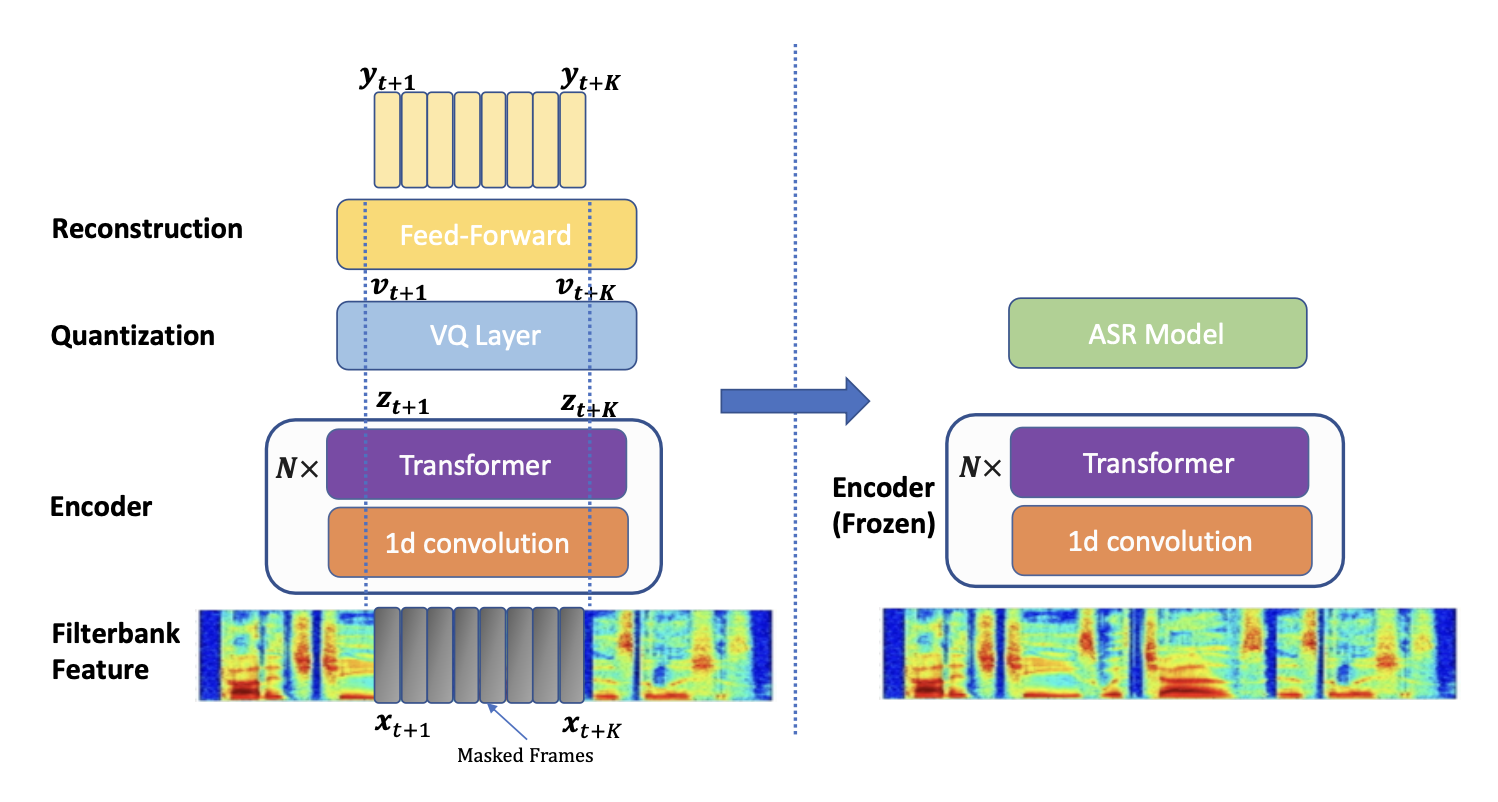
Image from the original DeCoAR 2.0 paper
2021: UniSpeech, HuBERT, XLS-R, BigSSL…
UniSpeech
In early 2021, Microsoft released a multi-task model that combines a self-supervised learning objective (same as wav2vec 2.0) with a supervised ASR objective (Connectionist temporal classification). This joint optimization allowed for better alignment of the discrete speech units with the phonetic structure of the audio, improving performance on multi-lingual speech recognition and audio domain transfer.
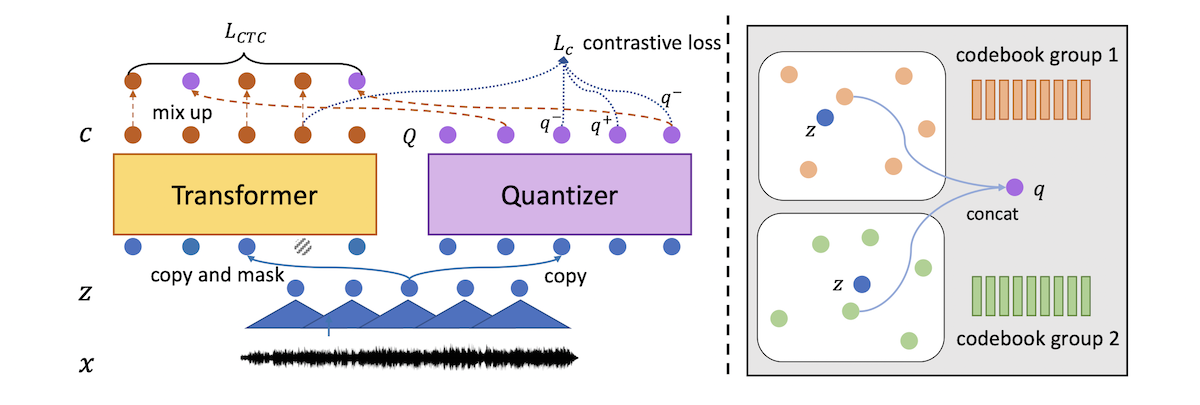
Image from the original UniSpeech paper
HuBERT
Coming also from Facebook/Meta AI, HuBERT re-uses the wav2vec 2.0 architecture but replaces the contrastive objective by BERT’s original masked language modeling objective. This is made possible by a pre-training process alternating between two steps: a clustering step where pseudo-labels are assigned to short segments of speech, and a prediction step where the model is trained to predict these pseudo-labels at randomly-masked positions in the original audio sequence.
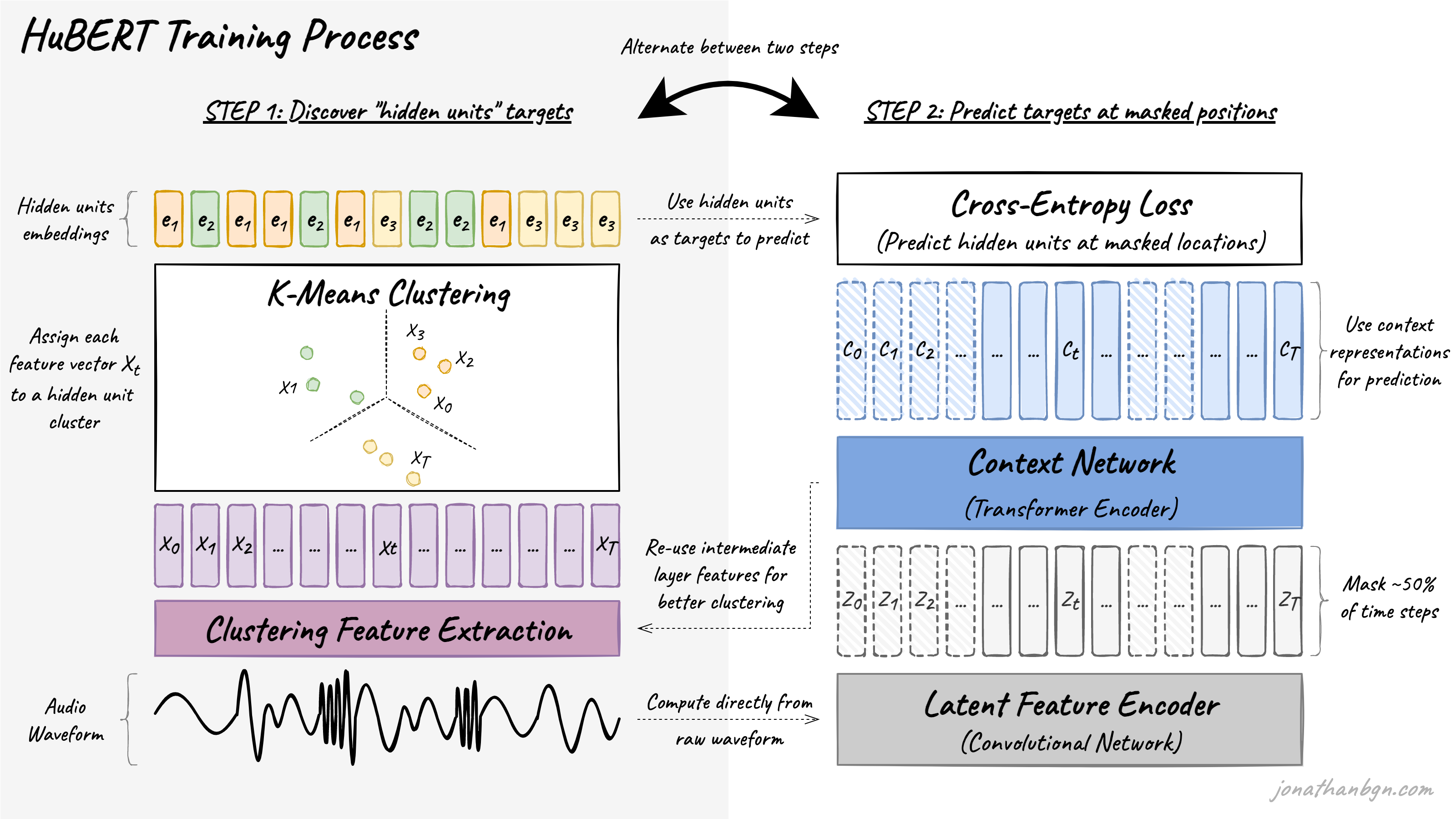
Image from HuBERT: How to Apply BERT to Speech, Visually Explained
w2v-BERT
w2v-BERT comes from researchers at Google Brain and MIT and combines concepts from wav2vec 2.0, BERT, and Conformer. Similar to w2v-Conformer, it re-uses the wav2vec 2.0 architecture but with transformer layers replaced by conformer layers. It also combines the contrastive loss of wav2vec 2.0 with the masked language modeling objective of BERT, allowing for an end-to-end training process of MLM without the need to alternate between processes like HuBERT. Its largest version, w2v-BERT XXL, scales to 1 billion parameters, similar to the largest w2v-Conformer model.
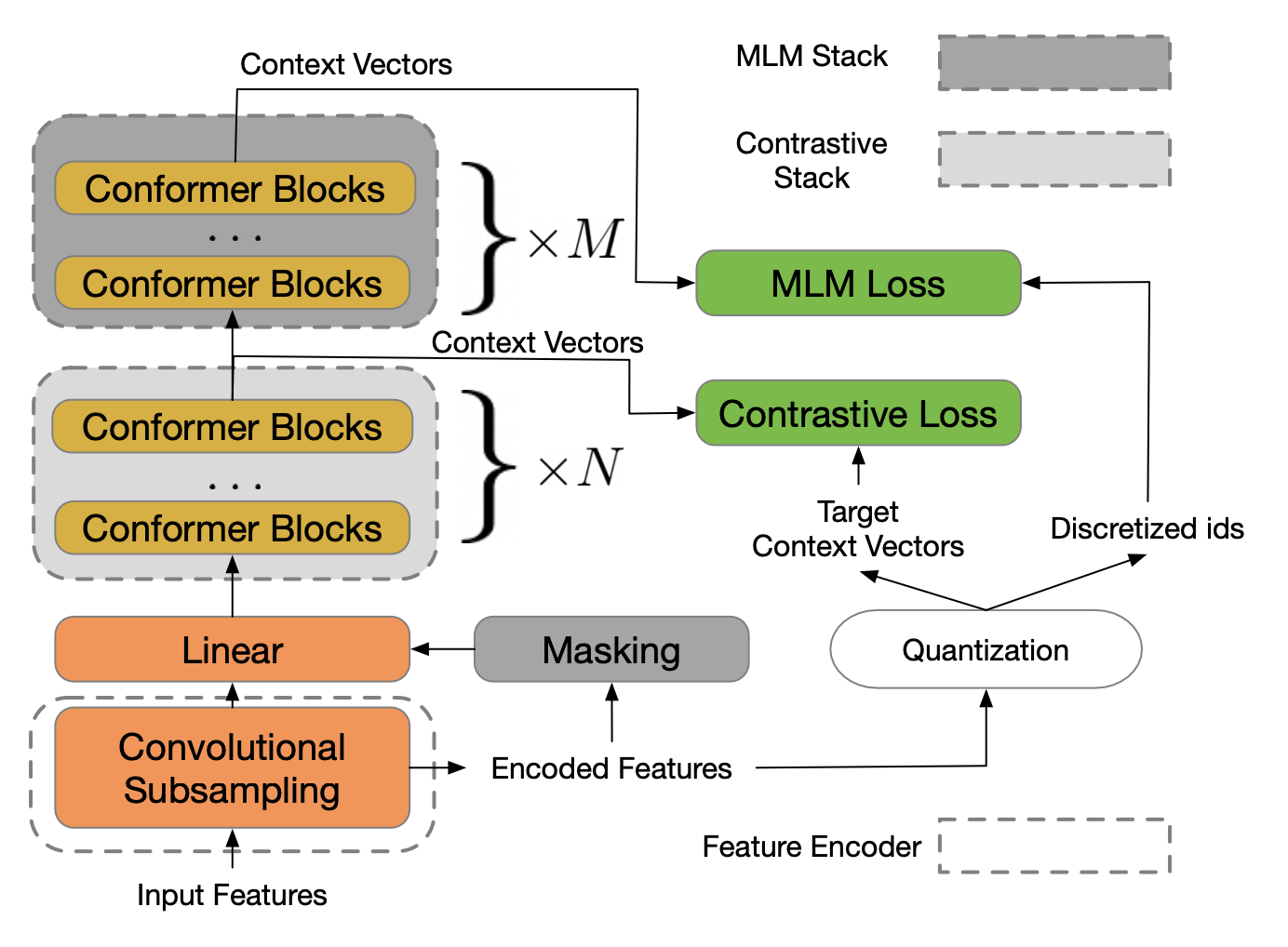
Image from the original w2v-BERT paper
XLS-R
A scaled-up version of XLSR-53, based on wav2vec 2.0. This very large model uses 2 billion parameters and is trained on half a million hours of speech in 128 different languages. This is more than twice the original 53 languages used by XLSR-53. XLS-R attains state-of-the-art performance in speech translation to English and language identification.
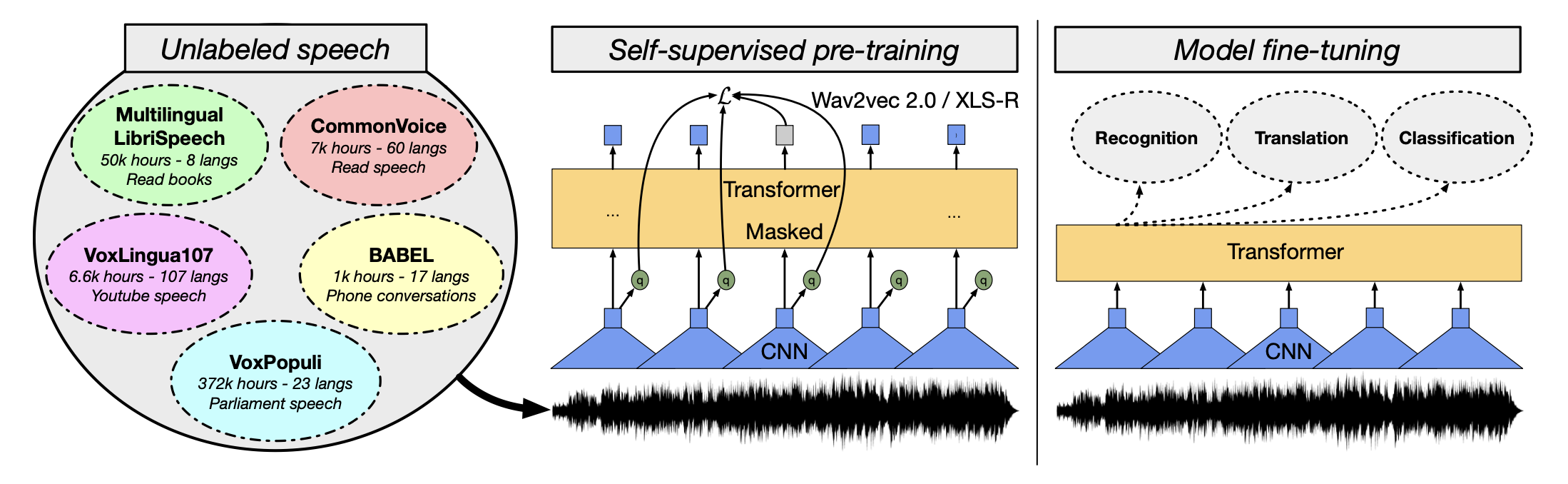
Image from Meta AI blog
The model also seems to perform as well as English-only pre-trained versions of wav2vec 2.0 when translating from English speech, hinting at the potential of multi-lingual models compared to monolingual ones.
BigSSL
BigSSL is a continuation of Google’s effort with its w2v-Conformer, scaling up both the model size and data (unlabeled and labeled data), and trained on approximately one million hours of audio. It is the largest of such speech Transformer models so far, with a staggering 8 billion parameters. This work highlights the benefits of scaling up speech models which, just like in natural language processing, benefit downstream tasks when trained on more data and with more parameters.
UniSpeech-SAT / WavLM
Both coming from Microsoft, the UniSpeech-SAT and WavLM models follow the HuBERT framework while focusing on data-augmentation during the pre-training stage to improve speaker representation learning and speaker-related downstream tasks.
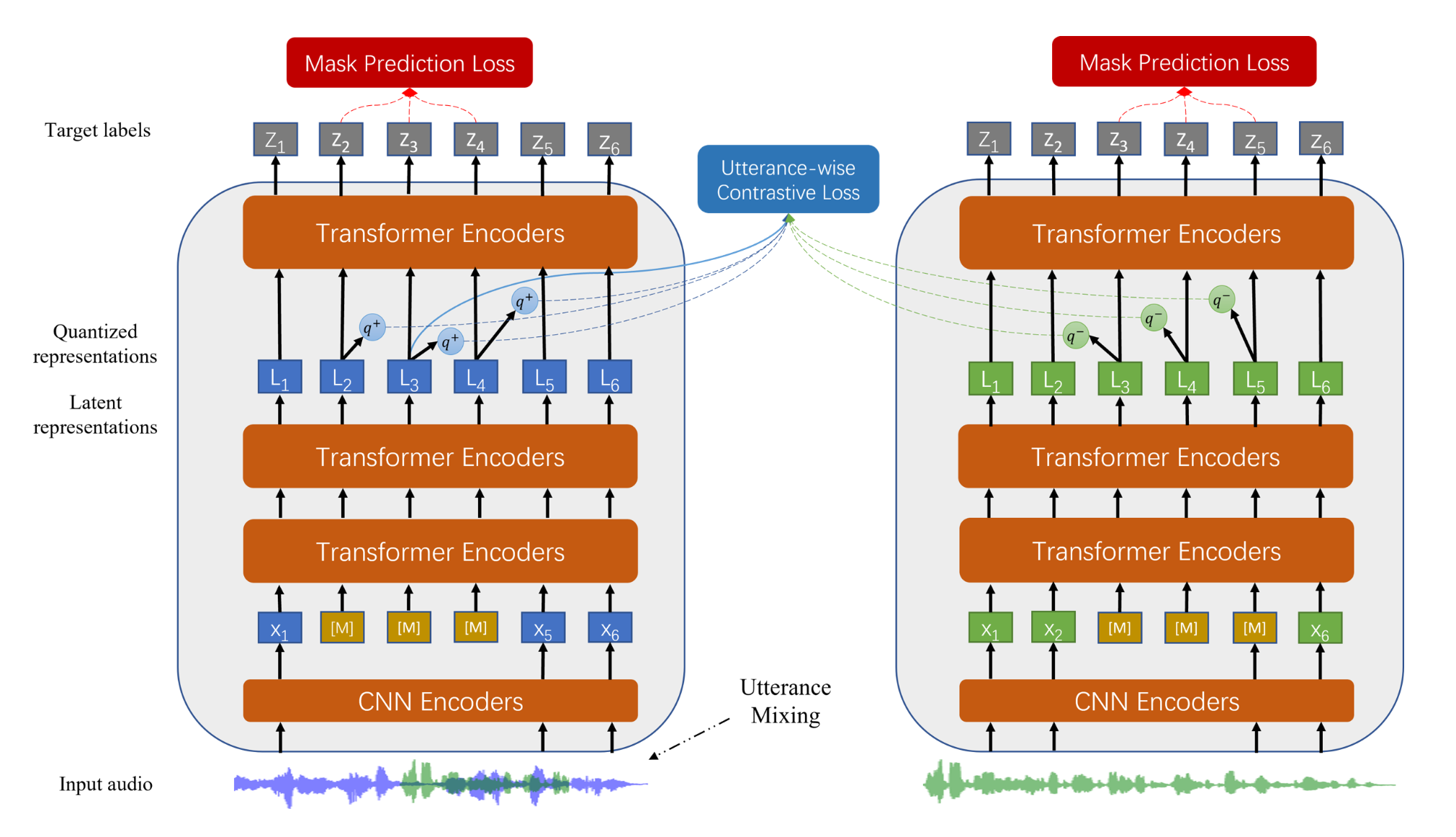
Image from the original UniSpeech-SAT
The WavLM model is especially efficient for downstream tasks, it is currently leading the SUPERB leaderboard, a performance benchmark for re-using speech representations in a variety of tasks such as automatic speech recognition, phoneme recognition, speaker identification, emotion recognition…
What does 2022 hold for speech processing?
In light of all the innovations that happened in 2021, we can be quite optimistic for 2022. We will most likely see even larger transformer models and better ways to transfer knowledge from pre-trained models to downstream tasks. In another post I’ve listed what I think could be some of the most interesting trends in speech processing for 2022.
Read next
2022 Trends for Speech Processing
HuBERT: How to Apply BERT to Speech, Visually Explained