HuBERT: How to Apply BERT to Speech, Visually Explained
Research in self-supervised learning for speech has been accelerating since the original wav2vec model released by Facebook AI in 2019. HuBERT is one of the latest of such models, with an open-source implementation already available in HuggingFace’s Transformers library.
Its main idea is to discover discrete hidden units (the Hu in the name) to transform speech data into a more “language-like” structure. These hidden units could be compared to words or tokens in a text sentence. Representing speech as a sequence of discrete units enables us to apply the same powerful models available for natural language processing, such as BERT.
The method draws inspiration from the DeepCluster paper in computer vision, where images are assigned to a given number of clusters before re-using these clusters as “pseudo-labels” for training the model in a self-supervised way. In HuBERT’s case, clustering is not applied on images but on short audio segments (25 milliseconds), and the resulting clusters become the hidden units that the model will be trained to predict.
Differences with wav2vec 2.0
Note: Have a look at An Illustrated Tour of Wav2vec 2.0 for a detailed explanation of the model.
At first glance, HuBERT looks very similar to wav2vec 2.0: both models use the same convolutional network followed by a transformer encoder. However, their training processes are very different, and HuBERT’s performance, when fine-tuned for automatic speech recognition, either matches or improves upon wav2vec 2.0. Here are the key differences to keep in mind:
HuBERT uses the cross-entropy loss, instead of the more complex combination of contrastive loss + diversity loss used by wav2vec 2.0. This makes training easier and more stable since this is the same loss that was used in the original BERT paper.
HuBERT builds targets via a separate clustering process, while wav2vec 2.0 learns its targets simultaneously while training the model (via a quantization process using Gumbel-softmax). While wav2vec 2.0 training could seem simpler as it consists of only a single step, in practice, it can become more complex as the temperature of the Gumbel-softmax must be carefully adjusted during training to prevent the model from sticking to a small subset of all available targets.
HuBERT re-uses embeddings from the BERT encoder to improve targets, while wav2vec 2.0 only uses the output of the convolutional network for quantization. In the HuBERT paper, the authors show that using such embeddings from intermediate layers of the BERT encoder leads to better targets quality than using the CNN output.
In terms of model architecture, the BASE and LARGE versions of HuBERT have the same configuration as the BASE and LARGE versions of wav2vec 2.0 (95 million and 317 million of parameters respectively). However, an X-LARGE version of HuBERT is also used with twice as many transformer layers as in the LARGE version, with almost 1 billion parameters.
Training process
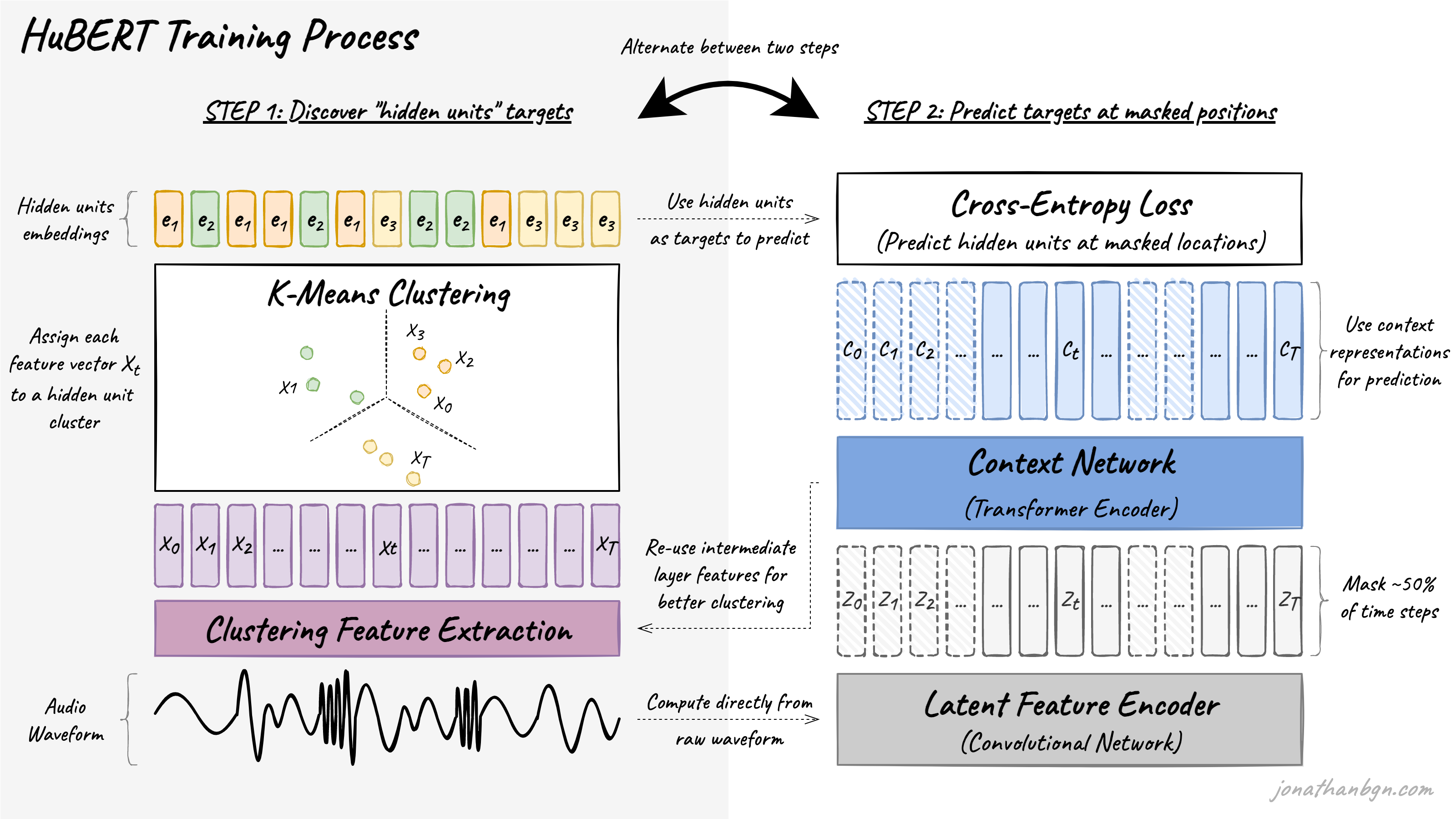
The training process alternates between two steps: a clustering step to create pseudo-targets, and a prediction step where the model tries to guess these targets at masked positions.
Step 1: Discover “hidden units” targets through clustering
The first step is to extract the hidden units (pseudo-targets) from the raw waveform of the audio. The K-means algorithm is used to assign each segment of audio (25 milliseconds) into one of K clusters. Each identified cluster will then become a hidden unit, and all audio frames assigned to this cluster will be assigned with this unit label. Each hidden unit is then mapped to its corresponding embedding vector that can be used during the second step to make predictions.
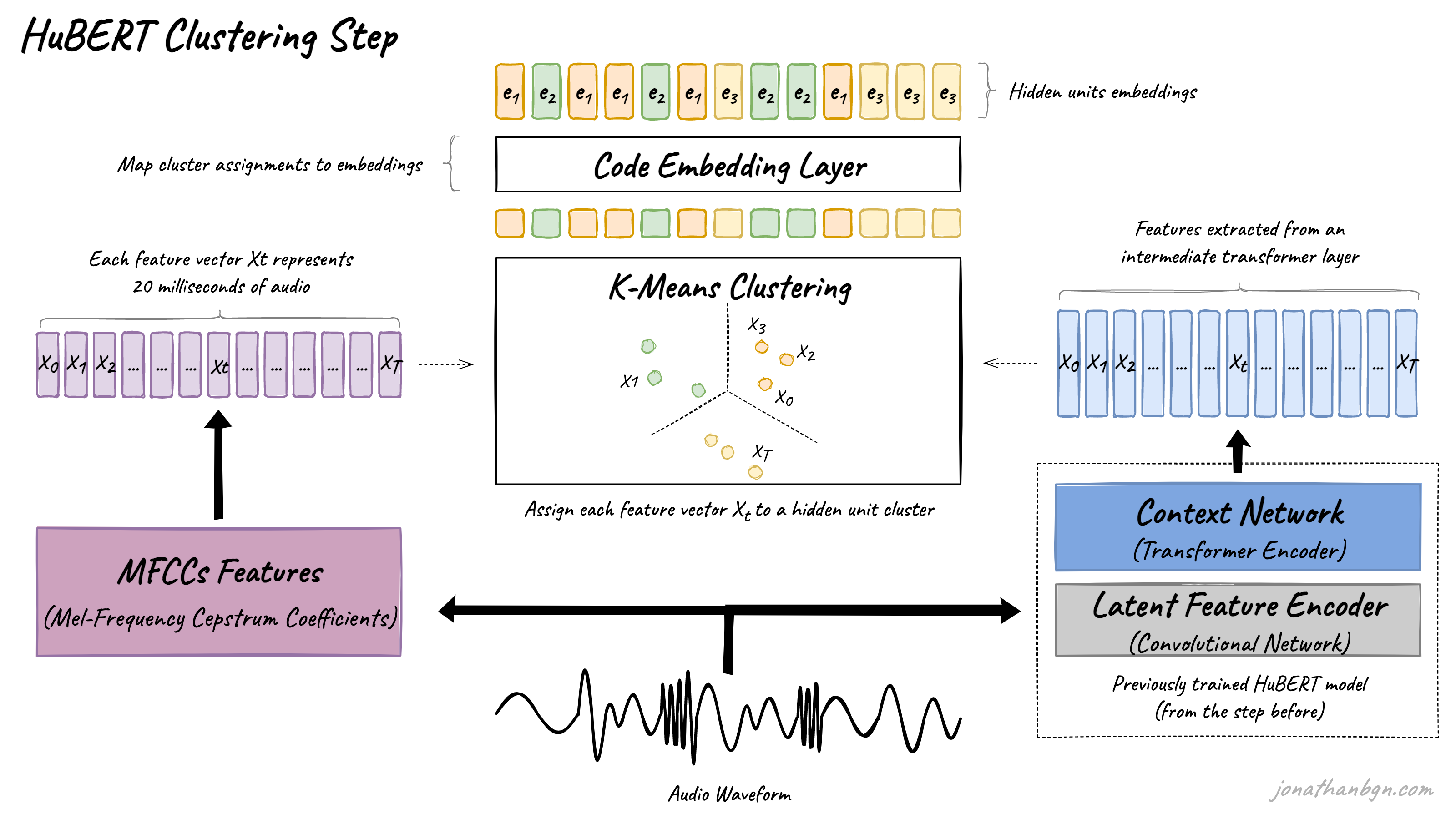
The most important decision for clustering is into which features to transform the waveform for clustering. Mel-Frequency Cepstral Coefficients (MFCCs) are used for the first clustering step, as these features have been shown to be relatively efficient for speech processing. However, for subsequent clustering steps, representations from an intermediate layer of the HuBERT transformer encoder (from the previous iteration) are re-used.
More precisely, the 6th transformer layer is used for clustering during the second iteration of the HuBERT BASE model (the BASE model is only trained for two iterations in total). Furthermore, HuBERT LARGE and X-LARGE are trained for a third iteration by re-using the 9th transformer layer from the second iteration of the BASE model.
Combining clustering of different sizes
The authors also experiment with a combination of multiple clustering with a different number of clusters to capture targets of different granularity ( vowel/consonant vs sub-phone states for example). They show that using cluster ensembles can improve performance by a small margin. You can find more details on this in the original paper.
Step 2: Predict noisy targets from the context
The second step is the same as for the original BERT: training with the masked language modeling objective. Around 50% of transformer encoder input features are masked, and the model is asked to predict the targets for these positions. For this, the cosine similarity is computed between the transformer outputs (projected to a lower dimension) and each hidden unit embedding from all possible hidden units to give prediction logits. The cross-entropy loss is then used to penalize wrong predictions.
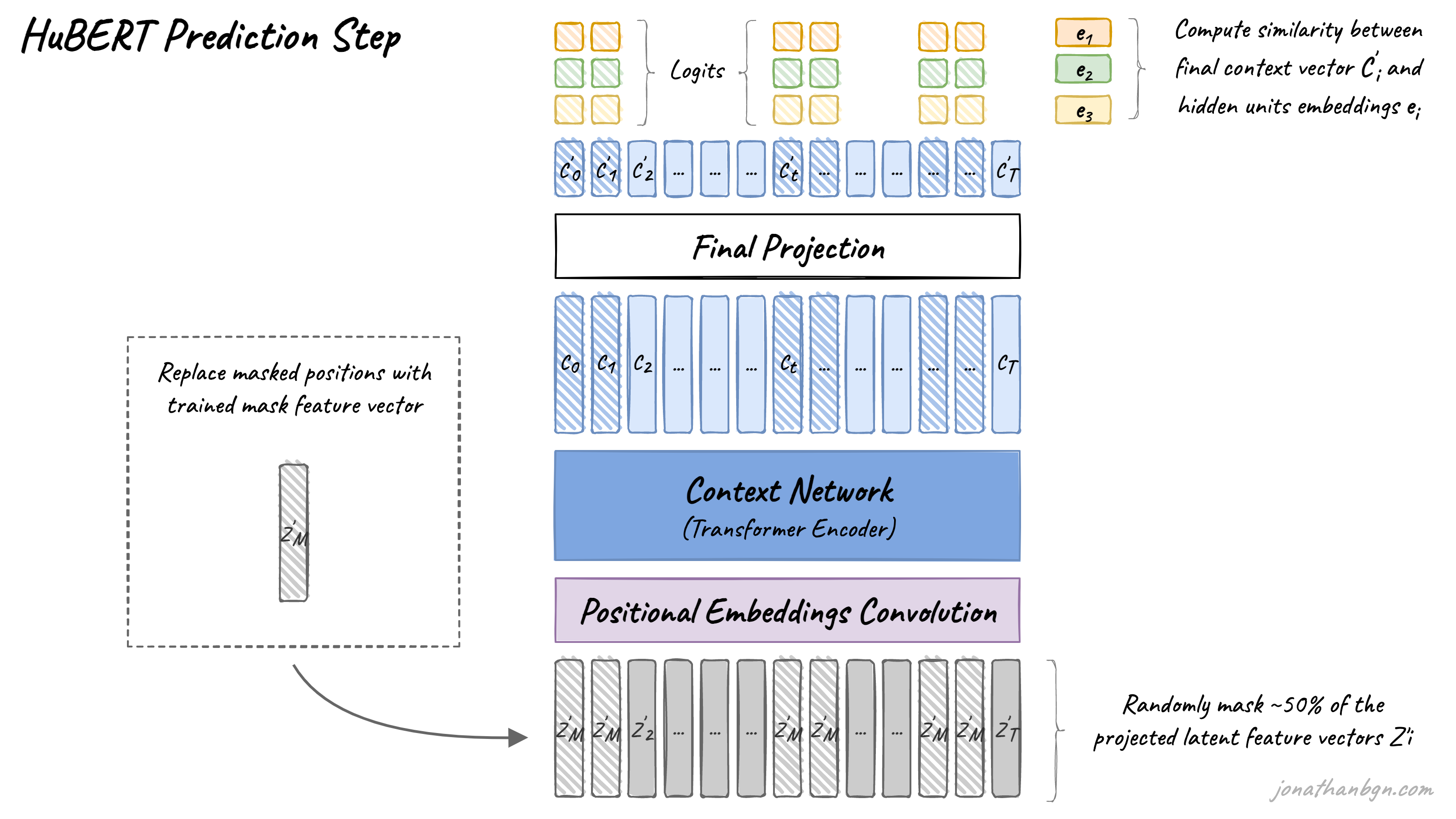
The loss is only applied to the masked positions as it has been shown to perform better when using noisy labels. The authors prove this experimentally by trying to predict only masked targets, only un-masked ones, or both together.
Conclusion
HuBERT can be used for automatic speech recognition like wav2vec 2.0 before it, but the paper authors also found that the representations learned can be very useful for speech generation. Indeed in another paper written by most of the same authors, they build a generative spoken language model able to generate speech without any use of text, opening the door to more applications for textless NLP.
Read next
An Illustrated Tour of Wav2vec 2.0