The Rise of Self-Supervised Learning
Since the deep learning wave started in the early 2010s, there has been much hype and disappointments. I feel that a big part of this is due to high expectations driven by research progress that do not translate so well in real-world applications. Hopefully, self-supervised learning might be able to close the gap between these two worlds. This learning paradigm is not new, but it has seen a resurgence of interest over the past few years thanks to mediatized successes like GPT-3 or BERT. Many AI pundits have also been relentlessly popularizing the idea, such as Facebook’s AI chief Yann Lecun with his cake analogy.
What is self-supervised learning? Why do we need it?
I will first share a bit about the motivation and idea behind the concept, and then give some examples of how it is used in the main machine learning domains today.
Today’s deep learning success is mostly about labeled data
By now, you must have heard once or twice about the importance of data. Yet not all data is equal. What deep learning practitioners care the most about is labeled data, manually annotated by humans. It is now commonly accepted that deep learning works incredibly well on tasks where large labeled datasets are available.
The most famous example of such large datasets is ImageNet, a collection of 1+ million of images manually annotated by humans. ImageNet was a critical component of the rise of deep learning, and AI researchers often talk about the ImageNet Moment. In 2012, a deep learning model called AlexNet trained on ImageNet surpassed all other methods on image classification for the first time. The major innovation behind this success was the availability of this huge collection of labeled data, rather than AlexNet’s architecture itself. Indeed, the AlexNet architecture is strikingly similar to the 1998’s LeNet-5 architecture, except of course that it is much larger and deeper1.
Problem: Labels don’t scale
While academic research often focuses on large clean labeled datasets like ImageNet, most data available for real-world applications is incredibly messy, and labels are extremely scarce. The problem is even worst for particularly niche applications or unique domains and languages.
Should we spend more effort to label existing data then? That has been the go-to solution so far, and an entire labeling industry is getting established to answer this need. However, deep learning has an insatiable appetite for labeled data. You can quickly need in the order of millions of labeled examples for your model to generalize effectively! Moreover, labeling data can be extremely costly and time-consuming. For many concrete use cases, this is not a practical solution.
Labels are expensive. Fortunately, unlabeled data is free!
On the other hand, there are more and more data available without labels out there. For many problem domains, you can collect large quantities of data from the Internet. Moreover, companies have access to troves of unstructured, unlabeled data from their day-to-day operations.
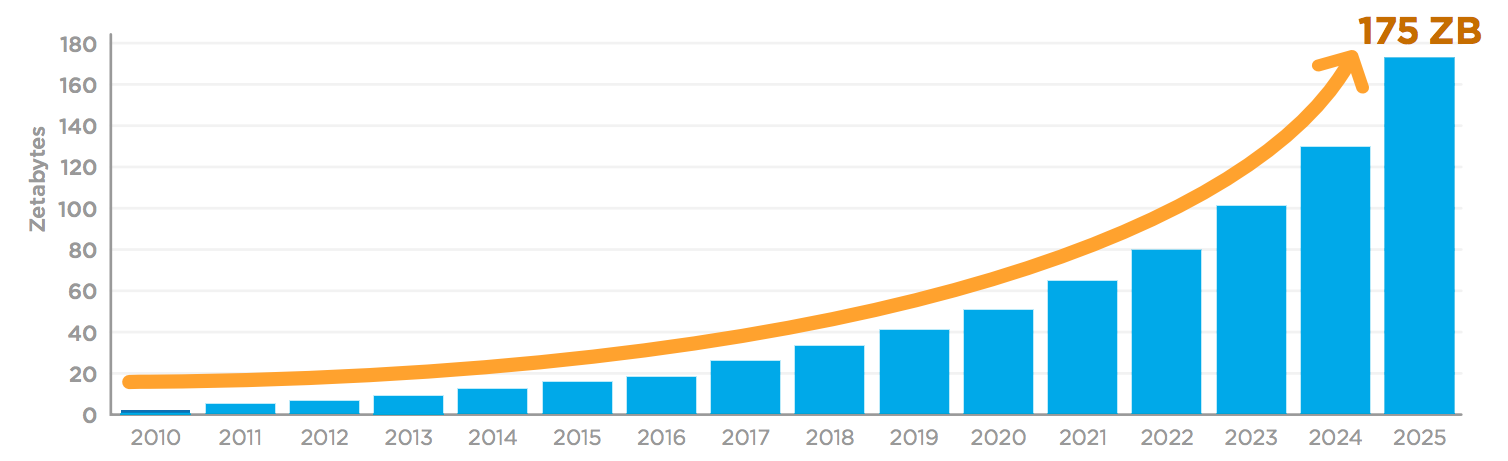
Annual Size of the Global Datasphere (Source: IDC Data Age 2025)
Is there any way we could leverage this immense pool of data? It turns out that self-supervised learning can help with just that.
Reducing the need for human labels
Self-supervised learning allows training on unlabeled data, thanks to automatic label generation. This is still a form of supervised learning: the model learns how to map inputs with labels. The only difference is that we don’t need humans to manually annotate the data beforehand.
How to generate these labels then? The most popular approach is to use one part of the input as the label itself. There exists many possible ways to do this:
- Remove a word from a sentence, which becomes the target label
- Hide one part of an image and let the model re-generate it
- Ask the model to predict the next frame in a video
- …
Since we automatically generate the target to be predicted, we can now use all data available, labeled or not. For many use cases, this opens the door to training on an (almost) unlimited amount of data! This is a game-changing paradigm that effectively shifts the bottleneck from data quantity to compute capacity.
A good example is a language model: a model trained to predict the next word in a sentence. Text is widely available, and we can automatically split a sentence into its beginning and the final word to predict. It costs nothing to create one labeled example, and the amount of textual data on the Internet is now the limit. As the amount of training data is no longer limited, computing power and model sizes now become the limits for improving performance. The recent GPT-3 model is the perfect example of this: we now need to build enormous models to take advantage of so much data. According to some estimates, training GPT-3 by yourself with current cloud platform offerings would require 355 years and $4,600,000!

A language model like the GPT family predicts the next token based on what came before.
A very short history of self-supervised learning
Despite the recent surge of interest in self-supervised learning, this is not a new idea. Back in 2006, Geoffrey Hinton et al. published a seminal paper about pre-training Restricted Boltzmann Machines in an unsupervised way followed by a fine-tuning phase. This led to a lot of interest in the method, but it quickly faded as people realized that if you have a large labeled dataset, then it is enough to train directly in a supervised way.
Yet the idea might be even older. The earliest usage of the term on Google Scholar is in a 1978 paper, and multiple papers were referencing it back in the 1990s. Even before the use of the term itself, related ideas like language models were already quite popular. The first N-Gram language models are at least as old as Claud Shannon’s 1948 seminal paper A Mathematical Theory of Communications, which set the foundation of Information Theory.
That the concept is now experiencing a resurgence is thus less due to a breakthrough in theory but more to the exponentially available quantity of unlabeled data and the increasing need to extract value from it.
Bridging the gap between research and real-life
Transfer knowledge to generalize better
The true power of self-supervised learning does not lie in using it just for a few tasks like language modeling for which we can generate an infinite amount of labeled data. The key is to use it as a transfer learning method, where we transfer the knowledge contained in a model trained on a task for which plenty of data is available to the objective task for which data is limited. This is usually done in two training steps. In the first step we pre-train our model in a self-supervised way on a pretext task such as language modeling (also called the auxiliary task in the literature). In the second step, we fine-tune our model on the downstream task, which is the one that we care about. This second step is done in a standard supervised way, trained on human-labeled data.
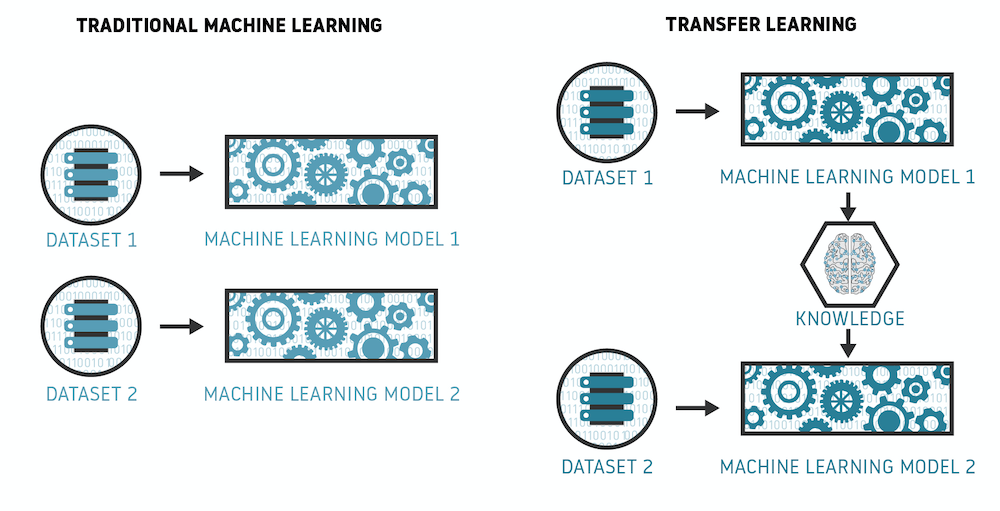
Transfer learning works by re-using knowledge of a model trained on another task for which data is abundant (Image credit)
An important point here is the choice of the pretext task. This task must make sense such that solving it must be in some way useful to the downstream task. In other words, the pretext task should force the model to encode the data to a meaningful representation that can be re-used for fine-tuning later. For example, a language model trained in a self-supervised way needs to learn about meaning and grammar to effectively predict the next word. This linguistic knowledge can be re-used in a downstream task like predicting the sentiment of a text.
Improve performance on small datasets
While we still need some domain-specific labeled data for the second fine-tuning step, pre-training first in a self-supervised way has been shown to immensely improve the performance on the downstream task, even when very few labeled data is available for fine-tuning. For example, the ULMFiT paper showed that it is possible to reach great performance for text classification with only 100 labeled examples. More recently, a new paper from DeepMind outperformed the original AlexNet performance on ImageNet with only 13 labeled examples per class.
Self-supervised learning does not remove the need for labeled data, but it greatly reduces the need for it and makes it practical to deploy deep learning models for use cases in which labeled data is (very) limited.
And this is exactly why it might be the key to unlock the promises of deep learning in real-world applications and for the industry. Since the digital revolution began, companies have been collecting tons of proprietary data in the hope of profiting from it in the future. However, they don’t know what to do with it so far as most of it is messy, unstructured, and most importantly unlabeled. Bringing self-supervised learning in the equation could help unleash the latent value from these tons of data.
The state of self-supervised learning in 2021
Natural language processing
NLP is the first field in which self-supervised learning first became hugely popular, and as such has many examples of the technique. The most straight-forward example that I already mentioned in the language model, predicting the next word in a sentence. Despite being one of the earliest examples of the method, it is still popular today due to big models like GPT-3.
Language models are far from being the only examples in the field. A variety of word embeddings approaches such as word2vec or GloVe also revolutionized the field back in the 2010s. The idea was simple, instead of predicting the next word, we could just ask the model to predict a word based on its context or vice versa. We then obtain distributed representations of words (embeddings) which encode meaningful information about words and can be re-used in all sorts of problems.
Today, the most popular self-supervised approach is arguably the masked language modeling one, which the now famous BERT model exemplifies. By “masking” random words in the text and asking the model to fill the holes, we can learn meaningful representations that can be later used or fine-tuned in a variety of downstream tasks.
The quest for the optimal pretext task is far from complete! Just this month at NeurIPS 2020, Facebook AI shared a promising new self-supervised learning technique: paraphrasing. Their model MARGE finds related documents and then paraphrases them to reconstruct the original. This approach even allows for good enough performance on some tasks without a fine-tuning step on extra labeled data.

Computer vision
Unlike NLP, self-supervision has not yet seen widespread adoption here, mostly because current techniques are still a bit too complex to implement. Yet this might change very soon. Influenced by the success of the concept in NLP, research has been very active in the area. This year alone, there has been an explosion of papers on self-supervised learning in image recognition. Performance obtained through self-supervision is starting to match end-to-end supervised models even when labeled data is abundant like for ImageNet.
Many kinds of pretext tasks are being used today, such as colorization (black & white to colors), patch placement (ordering patches cut from an image like a puzzle), or inpainting (filling an automatically created gap). One of the most interesting ideas of the moment is the one of contrastive learning. A neural network is trained to generate consistent representations between different views of the same image (randomly transformed by cropping or rotation), but distant representations between different images. A good example of the idea is the SimCLR framework from Google.
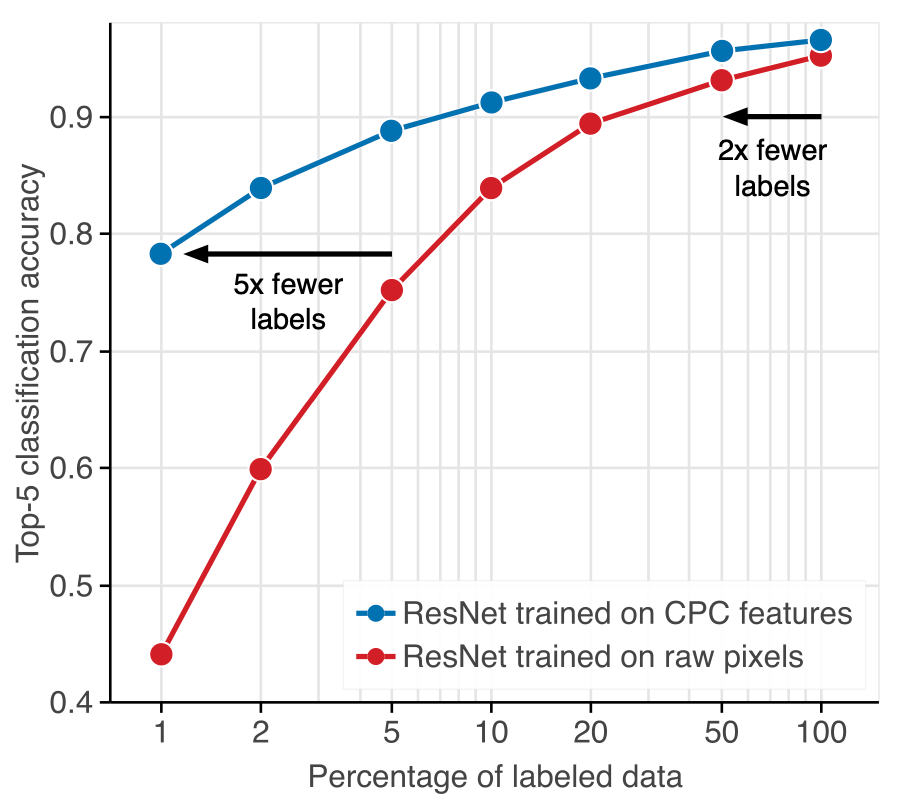
Data-Efficient Image Recognition with Contrastive Predictive Coding
There are still some important problems that must be solved before we see wider adoption of self-supervision in vision. Often, many “tricks” (data augmentation, negative sampling…) are used during the self-supervised phase, and these can be very domain-specific and hard to implement. Moreover, the losses can be quite complex, and difficult to optimize properly.
Speech processing
Last but not least, self-supervised learning is also just starting to gain traction in speech processing. I am personally very enthusiastic about the future of this field, as I’m currently working on Speech Emotion Recognition, a hard task for which labeled data is extremely scarce. Using self-supervised learning, we were able to beat strong baselines while using only 100 examples per emotion and improve upon the state-of-the art when using all data. I deeply believe that self-supervised learning is the key that will allow the emotion recognition field to make large progress in the coming years, and progress from basic emotion detection to more complex characterization of moods and states-of-mind.
The wav2vec model, inspired by word2vec, is in my opinion the most successful attempt so far for bringing self-supervised learning into the field. The model saw successive improvement and version 2.0 was just published at NeurIPS this year. While the model was originally only made of convolutional networks, the Facebook AI team then added a Transformer network to the architecture and, inspired by NLP, added an automatic discretization of inputs to be able to use some of the NLP models that work well on discrete data. The method allowed the creation of robust Automatic Speech Recognition (ASR) models with only 10 minutes of labeled data!

Wav2vec uses contextual representations to distinguish between real and fake future samples of audio. Here “CUH” is the correct sample.
Wav2vec is not the only self-supervised approach in this domain. Google AI has been working with the huge AudioSet dataset which contains more than 2 million audio clips to create unsupervised embeddings for speech. The resulting embeddings called TRILL allowed to reach very competitive performance and even state-of-the-art on a variety of tasks such as speaker identification, language identification, emotion detection, or even dementia detection.
The future will likely be self-supervised
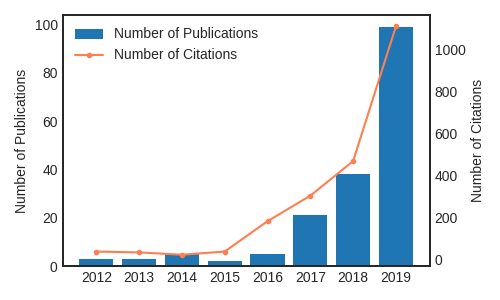
Number of papers containing the term “self-supervised learning”
I believe that self-supervised learning will soon become the gold standard in most fields of machine learning. As the techniques become better and deep learning frameworks remove implementation complexity, there will be wider adoption across all areas. We are also starting to see public repositories of models trained in a self-supervised way that anyone can download for their use case, such as on the HuggingFace website. The mass sharing of already trained self-supervised model will help democratize the use of the technique to every application.
Read next
Detecting Emotions from Voice with Very Few Training Data
Unleash GPT-2 (and GPT-3) Creativity through Decoding Strategies
Footnotes
-
Despite its similarity with LeNet-5, AlexNet was also the first model to stack convolutional layers directly on top of each other, removing intermediary pooling layers. ↩