Unleash GPT-2 (and GPT-3) Creativity through Decoding Strategies
GPT-3 has taken the software world by storm, putting the spotlight on Transformer models, which are now making their way into mainstream media such as The Economist or the Financial Times. A myriad of demos have made people woke up to the possibilities and new applications enabled by these large language models.
Still, GPT-2 and GPT-3 are not without flaws. They don’t handle well long pieces of text, have a tendency to contradict themselves, and get easily stuck into repetition loops. But I personally believe that one of the biggest issues with these models is the one of creativity: generating text that feels novel and original.
With this post I’d like to share my experience building Machine Wisdom, a website generating fun and inspirational quotes from GPT-2. I’ve explored different “decoding strategies”, various methods to decode/generate text based on the model’s prediction scores, in order to create quotes that are both interesting and surprising.
Creativity: The ability to produce or use original and unusual ideas, or to make something new or imaginative. (Cambridge Dictionary)
The “creative” language model paradox
The fundamental concept behind a language model such as GPT-3 is to predict the most likely next word or token, considering what came before. It does this by learning from millions of existing texts. However, if a language model assigns a high probability to what already exists, how can it generate novel or original ideas? How can it surprise people with new connections that were never made before? There is a deep contradiction here.

A language model like the GPT family predicts the next token based on what already exists.
Even worse, commonly-used generation methods like Beam Search increase the problem by sticking to the most likely paths, preventing any kind of creative branching. This leads to unsurprising and often bland content.
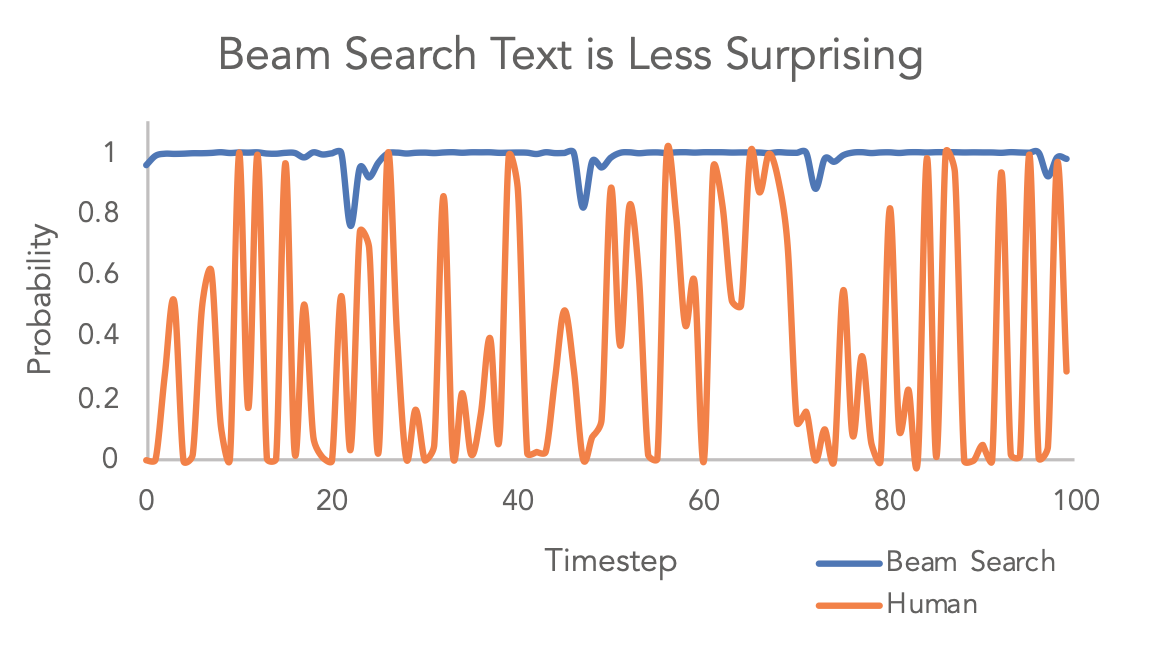
Figure from The Curious Case of Neural Text DeGeneration - Holtzman et al. (2019)
Generating “inspirational” quotes
I was curious to see if there was a way to go around that, so I decided to experiment with the simple task of generating artificial inspirational quotes. Quotes seemed like a great way to understand the limitations of these models. To be interesting, a quote must be surprising and original, but at the same time must make a lot of sense. They sounded like the perfect playground to explore creative generation.
The greatest glory in living lies not in never falling, but in rising every time we fall. -Nelson Mandela
The way to get started is to quit talking and begin doing. -Walt Disney
Your time is limited, so don’t waste it living someone else’s life. Don’t be trapped by dogma – which is living with the results of other people’s thinking. -Steve Jobs
Some of the most famous quotes of all time according to Hubspot.
Experimenting with different decoding strategies
To experiment with different generation methods, I have quickly fine-tuned GPT-2 on a dataset of around 500,000 quotes. I used the same parameters as in the first GPT paper for fine-tuning, training for 3 epochs with a learning rate of 6.25e-5 and a batch size of 32.
1. Greedy decoding: Generating what is most likely
The first thing I tried is to generate some quotes using the most basic decoding method of all: greedy decoding. I just took the most likely token at each step and generated a few examples by varying the prompt with different words such as “life”, “love”, etc…
Life is a journey.
Love is the only thing that can make you happy.
Work hard, but don’t let the work get you down.
The world is a stage, and the world is a stage, and the world is a stage, and the world is a stage, and the world is a stage, and the world is a stage.
These first generations seem to make sense but aren’t so original. A lot of them were also just memorized by the model. Life is a journey is a phrase that appears 58 times in the training dataset!
We also see one of our first examples of repetition with the world is a stage (which appears multiple times in the dataset too). This is a common problem with language models. They get easily stuck in repetition loops, especially when only picking the token with the highest probability.
2. Random sampling: Giving the model complete freedom
The extreme opposite of greedy sampling is random sampling. Instead of restricting the model to what is most likely, we allow it to theoretically choose any token in the vocabulary by sampling from the entire probability distribution. The most likely tokens still have a higher chance of being selected.
Songs are the pack of lights,searches,passions and desires you find in the moonlight
Removing making enhancers is self-invented.
I’m the magical, emerald home of you.
You cannot please everybody if you are singularly into the soul, a heart, a mind; EVERYONE!
A hero is a man who unlocks the limits of the imagination in a brave moment and threw himself into the disaster zone.
Here most quotes don’t make any sense at all. However, there is a much higher diversity in the language, grammar, and tone generated. Less common words like moonlight, emerald, singularly are making their apparition. The chances of generating something that already exists is also almost null. Despite the total non-sense, these sentences are in many ways more surprising and interesting than the ones from greedy decoding.
These two extreme generation methods are the perfect illustration of the creativity paradox introduced before. There is a fundamental trade-off between generating grammatically, logically correct text and generating original, surprising content.
3. Top-k sampling: Restricting the degrees of freedom
The most straight-forward intuition on how to solve this dilemma is to find a compromise between correctness and creativity. Surely there must exist a sweet spot where the model has just enough freedom to be creative without generating completely insane text.
In practice, it is quite hard to find this ideal spot. People have experimented with various filtering techniques to restrict the sampling space to correct options. In the GPT-2 paper, for example, all texts were generated by keeping the top-k most likely tokens at each step (with k=40):
A good marriage is a relationship of the soul not the body.
A strong government is an active and active government when it is an active and active people’s government.
We are all in this together, we are all living in one spirit.
It is not until you become a writer that you learn how to write your own stories.
To succeed you’ve got to be in the right position, to be in the right position, to be in the right position, to be in the right place, and to be in the right place.
Quotes generated this way can be quite erratic. It does generate decent results most of the time, but sometimes completely fail or get stuck in repeating loops. Moreover correct results seem to be quite “safe”, with simple word and grammar choice.
Most critics of top-k filtering focus on its fixed, static rule of keeping only the most likely k tokens. When the space of correct possibilities is large, top-k will stick to banalities. On the contrary, when there are only a few possibilities that make sense (less than k), then the model is allowed to sample absurd words.
4. Nucleus sampling: Loosening constraints dynamically
Holtzman et al. (2019) suggested nucleus sampling as a solution, where instead of restricting the sample space to a fixed number of tokens, we only keep the tokens for which the sum of the probability mass is at least p (this is also called top-p sampling).
In reality, as in movies, the truth can always be deceiving.
In order to experience the joy of life, we have to love it. It is in life that we learn to love ourselves.
My mother was a teacher, and my dad was a truck driver. Both were going to high school, so we were raised in a family with a lot of fun friends.
There are two ways of being lost in the jungle: to be free and free from your own.
The greatest success comes when you have a clear vision of what you want to do. The greatest success comes when you dare to dream, for a vision that doesn’t exist is the greatest accomplishment.
The quality of the generation is much better than top-k. The model falls less into repetition traps, and the results are slightly more original. However, we are still far from the creativity and originality of pure sampling. Is there really no way to give the model complete freedom, yet controlling for nonsense?
5. Sample-and-rank: Combining the best of both worlds
A recent paper from Google Research investigated the best way to generate human-like text in a conversational setting. Surprisingly they obtained the best results with a simple decoding strategy they called sample-and-rank. The idea is straightforward: we first generate N sentences from pure random sampling, we then choose the sentence with the highest overall probability. The overall probability is obtained by multiplying the individual probabilities of each word or token.
The beauty of this approach is that the model is completely free to sample any token from the vocabulary, yet we control for correctness afterward and filter out what doesn’t make any sense. In the original paper, the authors used N=20 and used a low temperature T=0.88 to “sharpen” the probability distribution and increase the probability of already very-likely tokens.
However, for my use case, I found it beneficial to actually “flatten” the distribution to generate more creative options and then increase the post-generation filtering with N=50. I also normalized the overall probability of each quote by its length to not penalize longer quotes.
Every time you want something badly, you have to start planning what to do with it.
We do not need miracles, miracles do need us.
You don’t need to take your time, you need to take an infinite amount of time.
A man should be content with what he has, and a man should be content with what he will.
Our faith is not based on what we think, but what we do. It is based on what we hope, and hope is based on what we dare do.
Conclusion
Sample-and-rank was the strategy that worked the best for my application. It created the most interesting quotes out of all methods, although there is still some occasional non-sense.
Keep in mind that all this is very experimental. Decoding strategies are a fast-moving field in NLP, and what I suggest here might not work as well for another application. It is best to experiment with different methods and see by yourself what works best for your specific use case.
If you want to see more, you can generate quotes by yourself on the Machine Wisdom website!