2022 Trends for Speech Processing
It’s an exciting time to be working in speech processing. The field has seen a lot of transformations and changes just over the past few years. In this post, I’d like to share my perspective on how I see the field moving forward in 2022, based on what we saw recently.
More Transformers
After revolutionizing the field of natural language processing, and then computer vision, the transformer architecture is now being adopted more and more in the speech processing community. It still feels like early days though, when you compare the diversity of transformer-based speech models compared to the multitude of such models in NLP.
Most visible so far has been the wav2vec 2.0 model as well as HuBERT, both coming from Facebook AI (now called Meta AI). The use of transformers, where each position attends to every other one, enables much richer contextual representations of audio sequences, compared to previous methods which relied on recurrent neural networks like LSTM to build sequence-level embeddings.
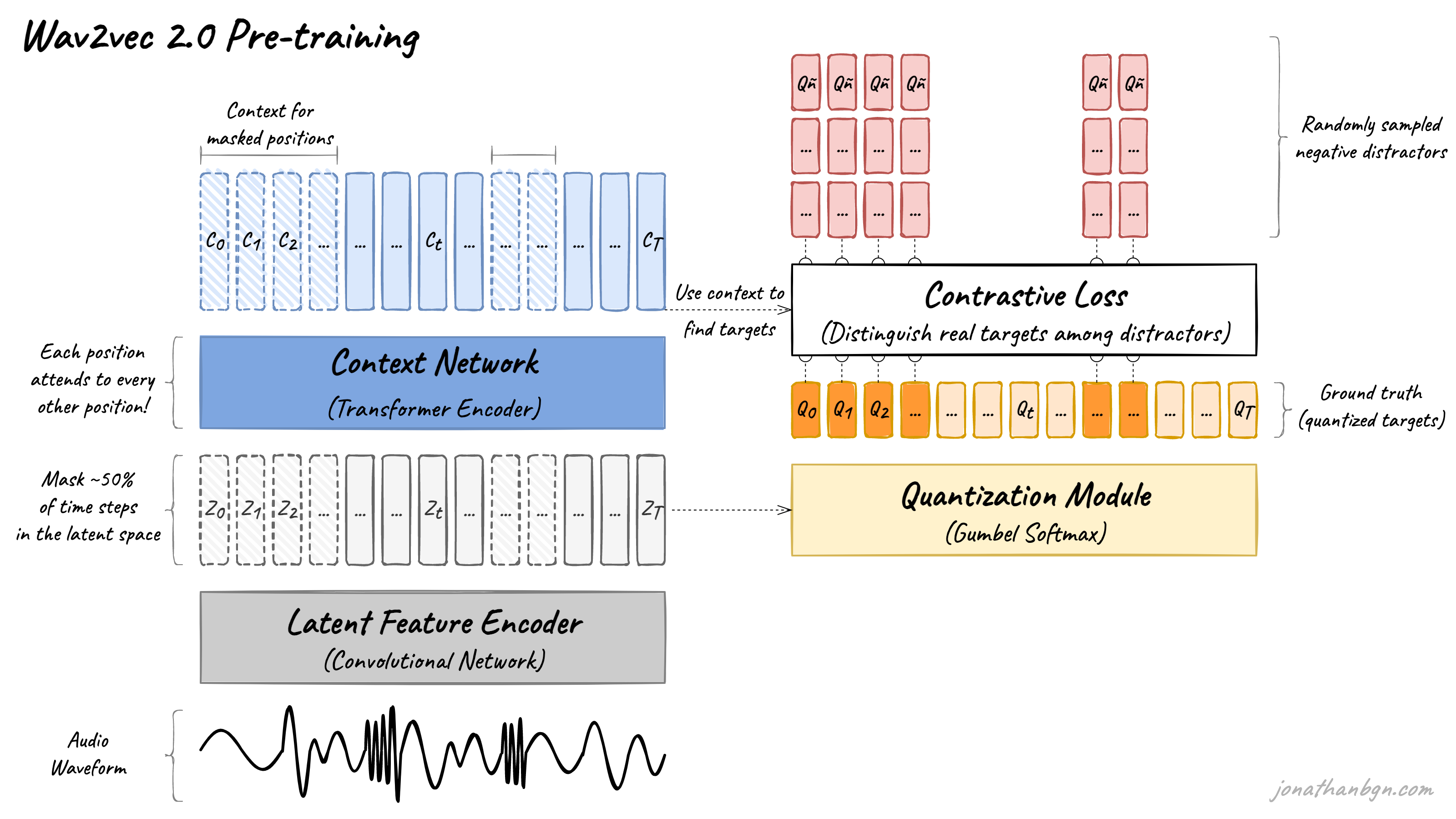 The wav2vec 2.0 model is based on the transformer encoder. Image from An Illustrated Tour of Wav2vec 2.0.
The wav2vec 2.0 model is based on the transformer encoder. Image from An Illustrated Tour of Wav2vec 2.0.
Larger Models and Datasets
As the field will likely follow what happened in NLP after the introduction of transformers, we’ll see bigger models emerge in the next year. We are still far from what we see in NLP with GPT-3 and its 175 billion parameters though. The largest transformer-based speech model (XLS-R) has slightly more than 2 billion parameters, around the same order of magnitude as the largest version of GPT-2, back in 2019.
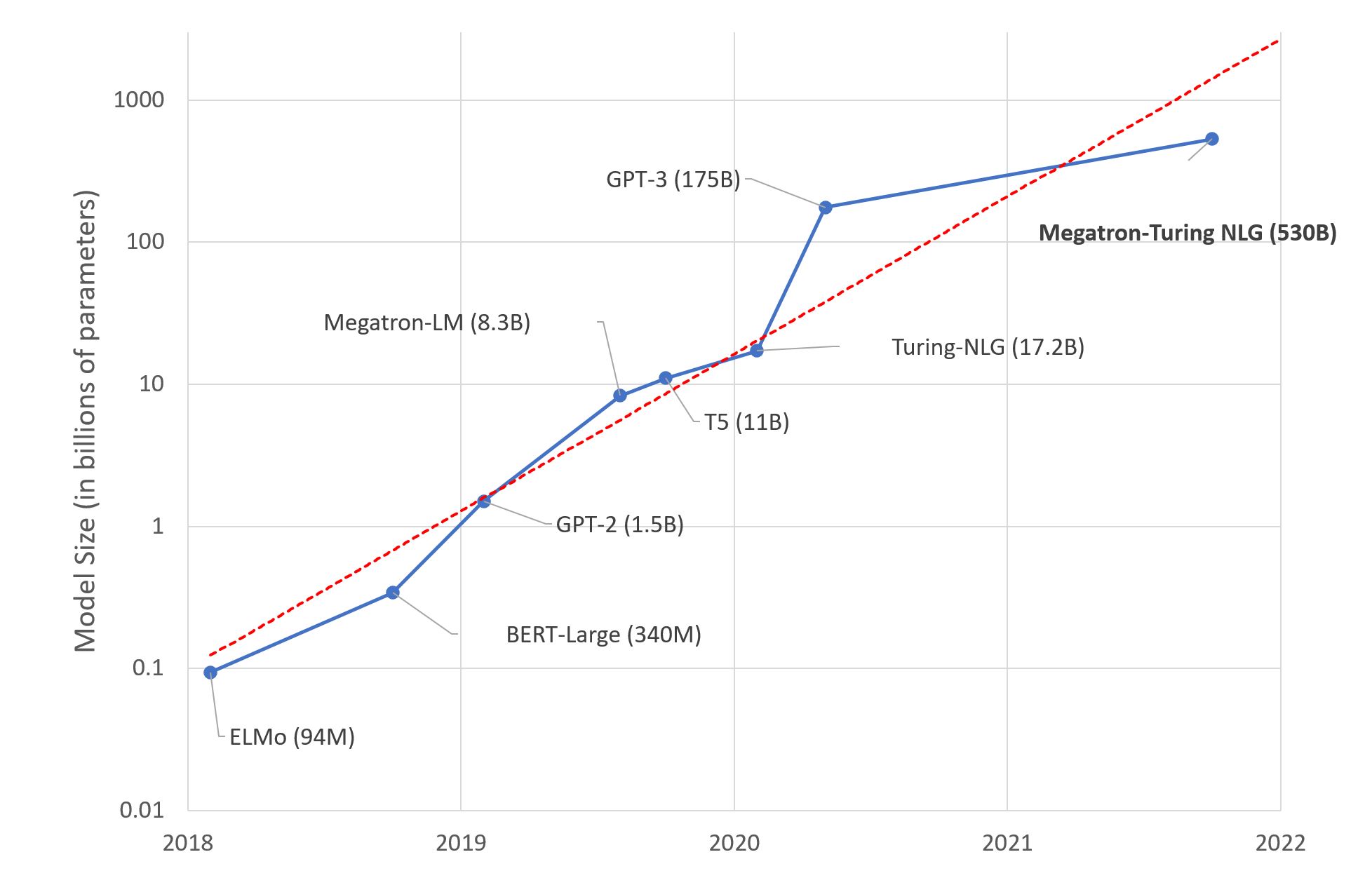
There seems to be no end in sight to NLP models scaling (image source).
Speech datasets too are being scaled up in size. The Common Voice initiative by Mozilla has already collected more than 13,000 hours of voice samples from 75,000+ speakers in 76 languages. The VoxPopuli dataset, open-sourced this year, offers 400,000 hours of unlabelled speech in 23 languages, making it the largest open speech dataset so far.
Less Supervision
As model sizes scale, so must training data. While we will see bigger labeled datasets, this will be far from being enough to feed the ever-larger capacity of these models. New approaches will likely be developed to train larger models more effectively in a self-supervised way, without the need to label data. We already saw a lot of different self-supervised training methods based on contrastive losses or unsupervised clustering to create pseudo-labels. More will come.
Fully unsupervised ASR systems are also starting to make their apparition: wav2vec-U, released this year, shows comparable performance to the best supervised models from only a few years ago, while using no labeled data at all.
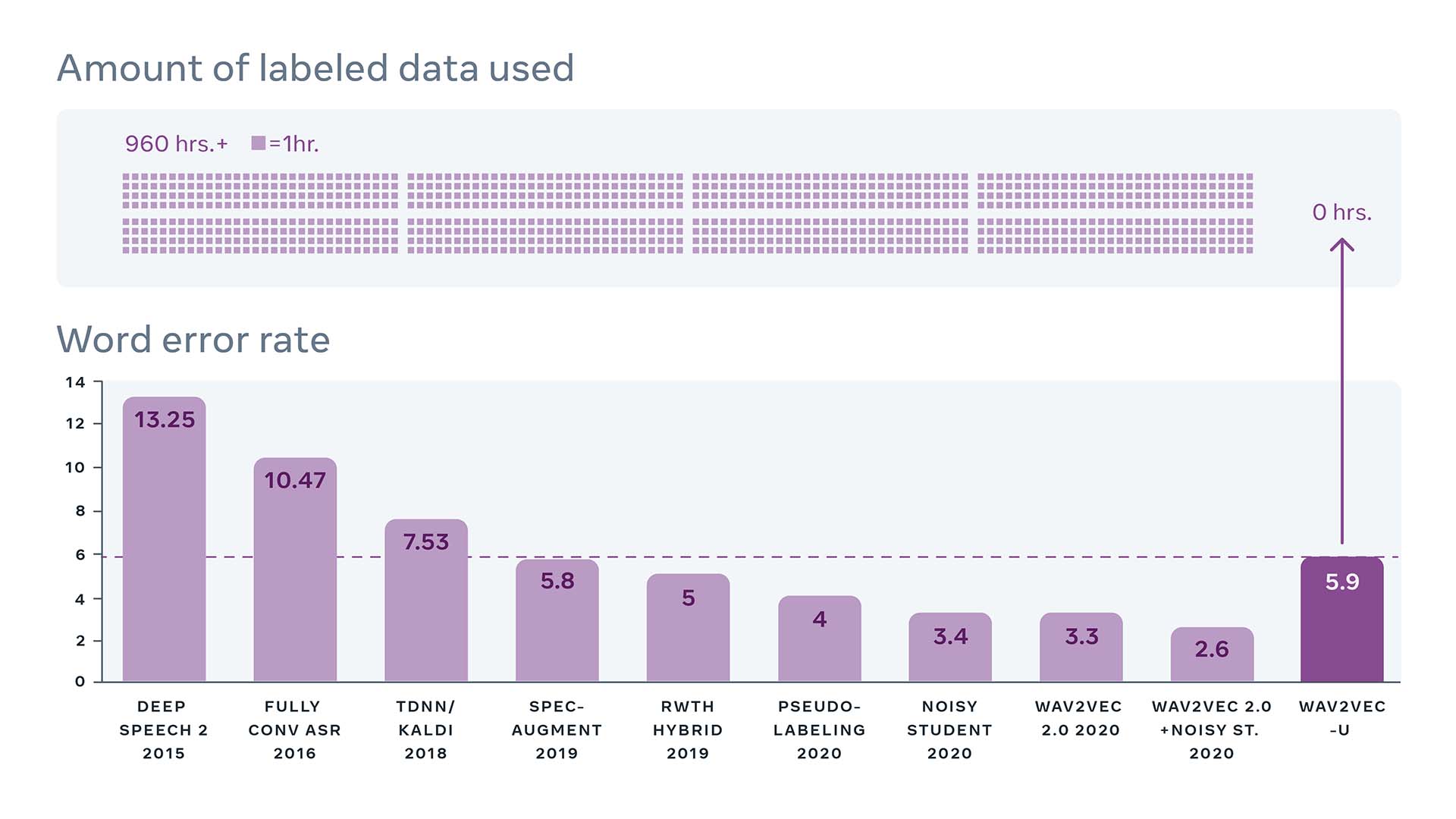 Wav2vec-U shows impressive performance on speech recognition without using any labeled data (Librispeech benchmark) (image source).
Wav2vec-U shows impressive performance on speech recognition without using any labeled data (Librispeech benchmark) (image source).
Multilingual Models
The rise of self-supervised learning has opened the door to effective speech recognition for low-resource languages for which labeled datasets aren’t available, or too small to be able to generalize from. The just-released XLS-R model, the largest of such models yet with over 2 billion parameters, has been trained on 128 languages, more than twice its predecessor. Interestingly, such large multilingual models improve performance much more when scaling the model size. This will probably lead to a preference for multilingual models over single language ones in the future.
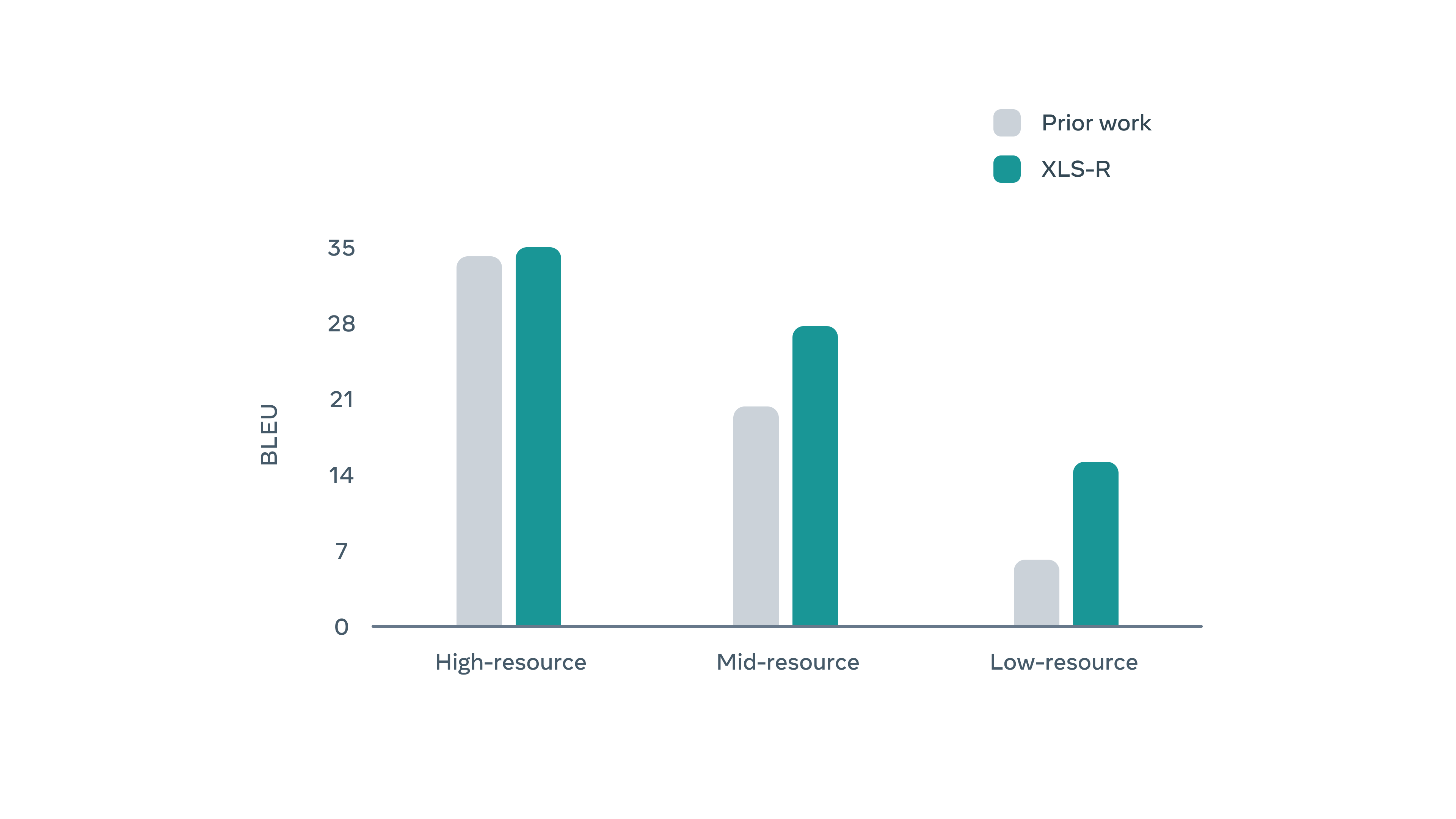 Speech translation performance of XLS-R from target language to English (image source).
Speech translation performance of XLS-R from target language to English (image source).
Textless NLP
Generative models like GPT-3 are certainly impressive, but they don’t capture all the subtlety of languages. This year researchers at Meta AI released the Generative Spoken Language Model (GSLM), capable of generating speech continuation without any dependency on text. This kind of textless NLP model enables much richer language expression by capturing much more para-linguistic information than just semantics. Tone, emotions, speakers voice characteristics… all these elements can now be encoded both for classification or generation.
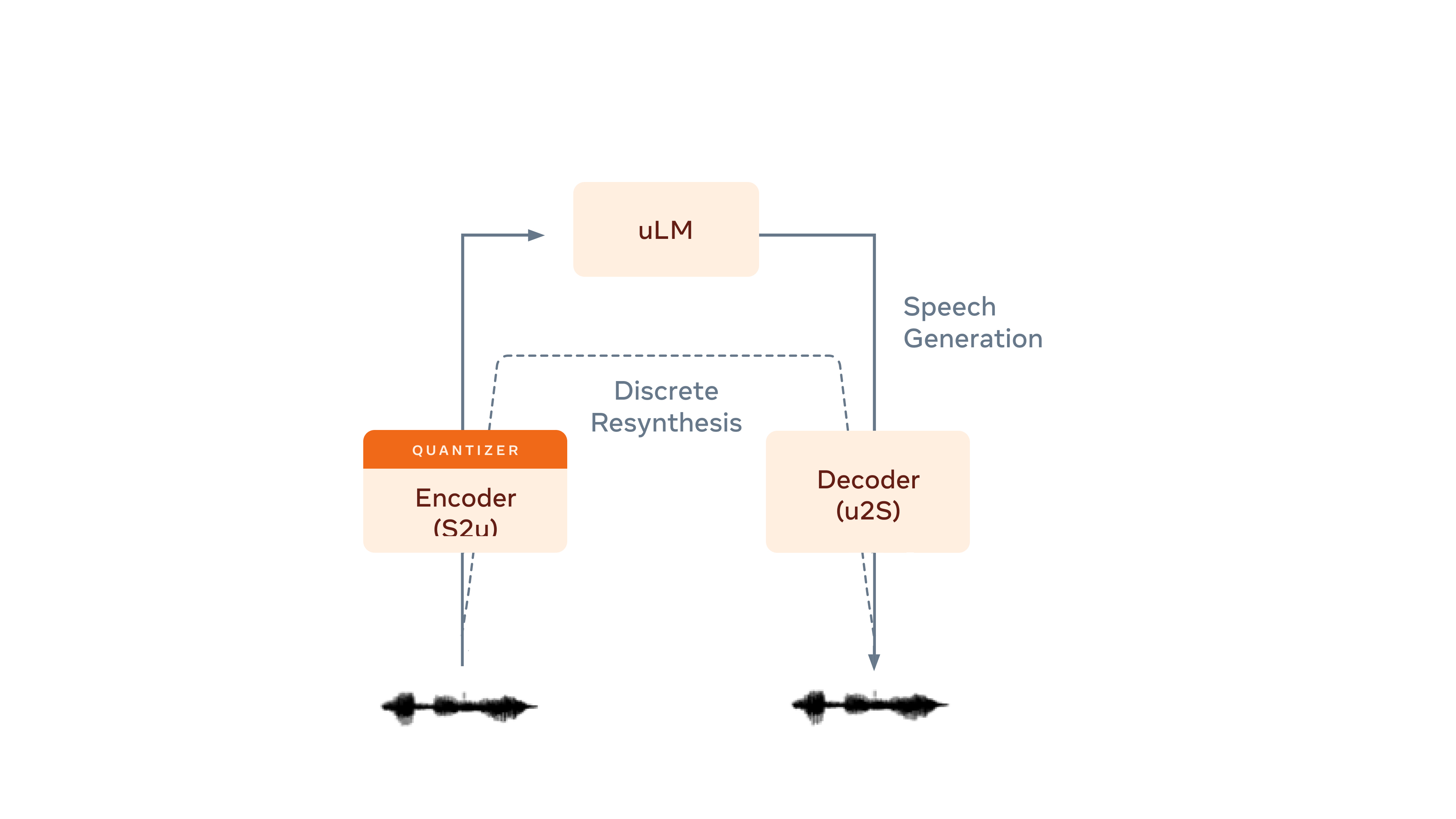 Architecture of the Generative Spoken Language Model, a textless generative model (image source).
Architecture of the Generative Spoken Language Model, a textless generative model (image source).
Such progress in speech processing could lead to many breakthrough applications, like expressive searchable speech audio, better voice interfaces and assistants, and immersive entertainment.
Better Libraries and Tools

Speech processing used to be much harder, but things are now changing fast. This year, the popular HuggingFace Transformers library started implementing speech models like wav2vec 2.0 and HuBERT. The SpeechBrain tookit has also seen much progress, and the TorchAudio library got some serious improvements this year, with new models added like Tacotron2 as well as easy access to some of the most popular speech datasets. We should expect more to come soon. Exciting times ahead!