Detecting Depression with Machine Learning: The Why and the How
Over the past decade, there has been tremendous progress in using artificial intelligence to better understand people. From natural language understanding to recognizing people’s emotions, deep learning has enabled a whole new set of applications that will profoundly change the way we interact with machines.
One of the most promising applications is in mental health, where machine learning could provide great value to both doctors and patients. Especially a lot of attention has been given to automatic depression detection, and how to use machine learning to help with screening, diagnosis, and monitoring. In this post, I’d like to give an overview of what’s being done and the benefits of a more automated approach.
The rising burden of depression worldwide
Cases of depression increased by nearly a fifth during 2005-15. It is estimated that around 15% of people worldwide experience depression at some point in their lifetime. The Global Burden of Disease Study, which compares the number of years lost due to ill-health, disability, or early death between 369 diseases worldwide, found that years lost due to depressive disorders increased more than 60% between 1990 and 2019. This sets depression as the 6th most burdensome disorder for adults aged 25-49, before strokes or diabetes.
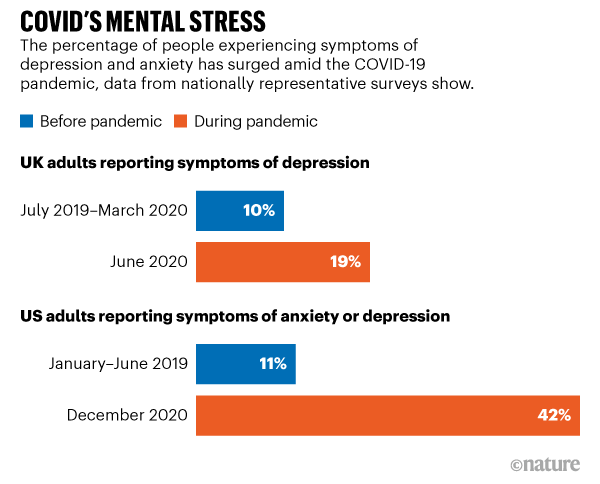
Image credit: COVID’s mental-health toll: how scientists are tracking a surge in depression
The Covid 19 pandemic has only made the problem more urgent. Depression and anxiety issues are surging worldwide since the beginning of the pandemic, and researchers are increasingly worried about the long-term effects of Covid on mental health.
How can doctors tell if you are depressed?
The biggest problem for diagnosing depression is the lack of any objective laboratory test, unlike other medical branches. For example, if a doctor suspects a case of diabetes, a simple blood test to measure glucose content can be done. There is no such thing for detecting depression, so psychiatrists have to rely on their own judgment and recognizing patterns of symptoms.
The confusion and disagreement around the differences between mental health diseases are also not helping the task. There is a large overlap of symptoms between depression and other mental health conditions. Less intense but persistent forms of depression, like dysthymia, are also classified separately. This complexity has led to intense efforts to improve the reliability of depression diagnosis: that is doctors should all make the same judgment for patients with the same set of symptoms.
DSM-5, the bible of psychiatrists

One of the most popular systems to standardize the classification of mental health conditions like major depressive disorder is the Diagnostic and Statistical Manual of Mental Disorders, which also goes by its nickname the DSM.
In the latest 5th edition of the DSM, an individual should be diagnosed as depressed if he/she is experiencing five or more of the following symptoms during at least a 2-week period1:
- Depressed mood most of the day, nearly every day.
- Markedly diminished interest or pleasure in all, or almost all, activities most of the day, nearly every day.
- Significant weight loss when not dieting or weight gain, or decrease or increase in appetite nearly every day.
- A slowing down of thought and a reduction of physical movement (observable by others, not merely subjective feelings of restlessness or being slowed down).
- Fatigue or loss of energy nearly every day.
- Feelings of worthlessness or excessive or inappropriate guilt nearly every day.
- Diminished ability to think or concentrate, or indecisiveness, nearly every day.
- Recurrent thoughts of death, recurrent suicidal ideation without a specific plan, or a suicide attempt or a specific plan for committing suicide.
The DSM has been overly criticized for its rigidity and sometimes arbitrary choices (why should five symptoms be enough and not four or six?). Diagnosis criteria have been updated over time, but changes are not always welcome. For example, there have been concerns that the latest edition of the DSM now classifies normal “grief” as major depression.
Assessing depression severity
To assist doctors in the diagnosis and monitoring of their patients, a variety of tests and questionnaires have also been developed. Some need to be conducted by a doctor, who questions the patient to observe and rate eventual symptoms, but others can be self-performed by the patients themselves. The outcome of such tests is a final score that classifies the patient into different categories such as no depression, mild depression, or severe depression. The gold standard of such assessment tools is the Hamilton Rating Scale for Depression (HAMD), but many more exist and are used in different situations.
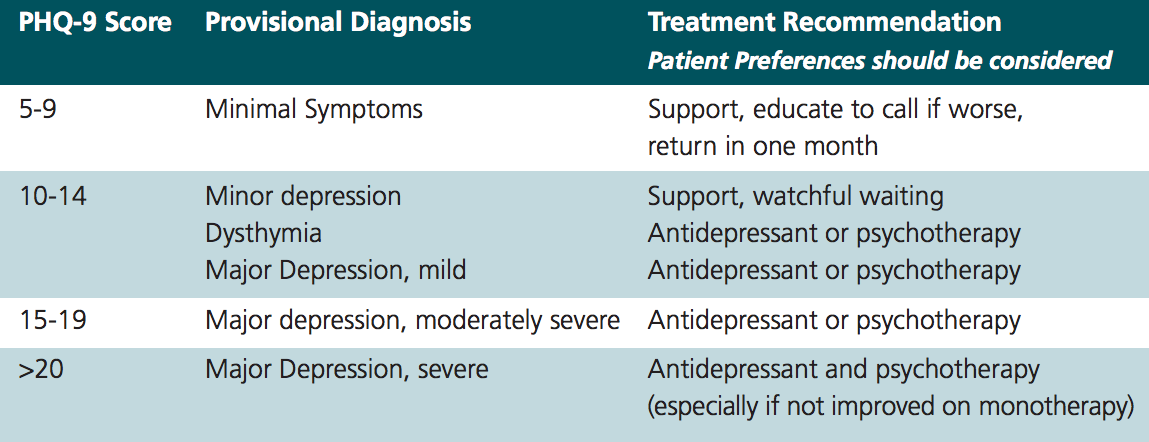
A questionnaire worth mentioning is the PHQ-9 (Patient Health Questionnaire). It is often used for labeling datasets before training machine learning models, mostly because of its simplicity: it consists of only 9 questions about the loss of appetite, energy, sleeping trouble, etc. for which patients can answer from “Not at all” to “Nearly every day”. Patients can self-conduct the questionnaire in less than 3 minutes. This convenience makes it an ideal choice for regular testing over long periods.
Why automatic depression detection is a good idea
The diagnosis process is unreliable

Despite the standardization efforts mentioned above, health care professionals still don’t agree on the exact requirements and threshold for depression. A meta-analysis across 41 studies found that general practitioners are only able to identify depression in 47% of cases. Even experienced psychiatrists and psychologists often come up with different diagnoses for the same patients, in more than 30% of cases. Interestingly, there are about the same number of research papers claiming that depression is over-diagnosed as claiming it is under-diagnosed.
There are important consequences to a wrong diagnosis for treatment. The World Health Organization stated that a major barrier to effective care is inaccurate assessment: in countries of all income levels, people who are depressed are often not correctly diagnosed, and others who do not have the disorder are too often misdiagnosed and prescribed drugs. In the US, antidepressants are now the 3rd most common prescription medication.
Doctors want better tools
An extensive study by Google has shown that many psychiatrists don’t use current diagnostic tools, often perceived as too burdensome or not reliable enough. More accurate tools are needed, which should be focused on assisting psychiatrists in their decision-making rather than trying to replace humans in the diagnosis process. The combination of subjective and automated assessments will lead to the most benefits.
Mental health needs a more personalized approach
The current diagnosis process is strongly dependent on a single point in time when the doctor interviews the patient. This can overestimate or underestimate the severity of depression depending on the mood swing of the individual. More meaningful monitoring along longer periods will help set up a personalized “normal baseline” for each individual and detect sudden variations in time.
Most sufferers don’t get any kind of help
Between 76% and 85% of depressed people in low- and middle-income countries receive no treatment for their disorder, mostly due to a lack of resources and trained doctors. Machine learning-based approaches could help to scale diagnosis and monitoring solutions to a much larger population worldwide, especially in countries with lower resources.
Social stigma is also stopping people from seeking help. 92% of people believe that admitting mental health problems such as depression would damage their career, according to a survey in the United Kingdom. Much too often depressed individuals believe that their condition is the result of personal deficiencies such as “being too weak”, rather than seeing it as a chemical imbalance problem that is out of their control. Such beliefs prevent people from speaking up. This phenomenon is even worst in some parts of Asia where culture tends to put blame on individuals failing to fulfill their role in society.
Using technology could be a less intimidating first step for many of the people who suffer from depression, helping them to put a word on their trouble and pointing them to potential solutions.
Current approaches in machine learning
Electroencephalography
EEG or Electroencephalography is used to record the electrical activity of the brain via electrodes placed along the scalp. Already used today to diagnose epilepsy and memory/sleep disorders, it has been a natural candidate to find an objective marker for depression. This is exactly what one of Google X’s moonshot projects decided to do. Project Amber, as it was called, developed a prototype that was as easy to use as possible for medical practitioners.
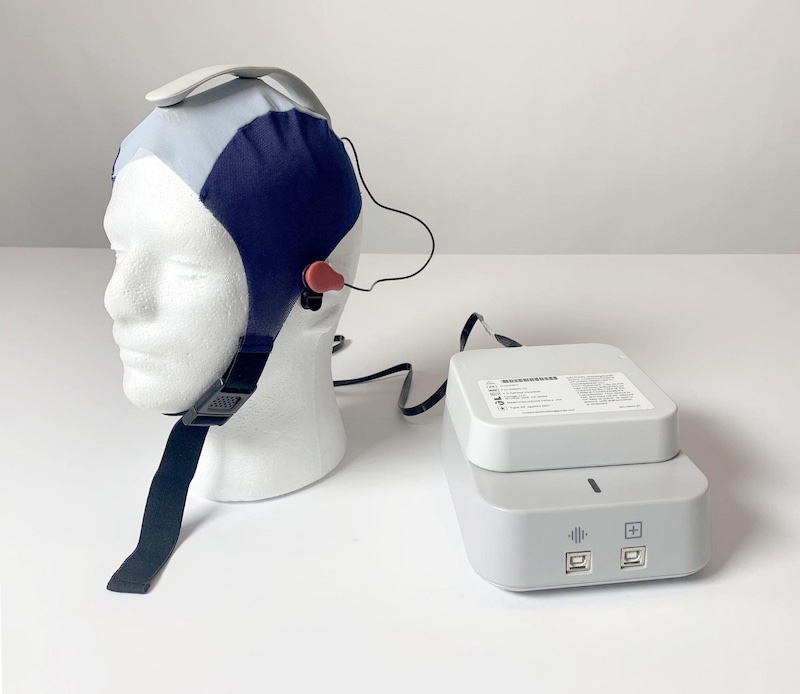
The main challenge when trying to make sense of electroencephalograms is to filter out the noise and extract relevant signals. Project Amber’s team collaborated with DeepMind to solve this problem via unsupervised representation learning, a machine learning technique that tries to extract the most “meaningful” bits of information in the signal by training on large quantities of unlabeled data.
Unfortunately Project Amber did not succeed in finding a reliable single marker for depression and was shut down in 2020. However, the project’s team still believes in the potential of the technology, and has open-sourced their hardware design and software in the hope that others build on top of their work.
Social media and linguistics
Another line of research has been to use behavioral and linguistics information from social networks like Twitter, Reddit, Facebook, Instagram, etc. Researchers have built algorithms that use everything from the content posted by the user to its activity/interactions (likes, shares, posting frequency), social network graphs, and demographics information.
Reported results have been promising, but concerns have been raised about the design of many studies, specifically about how users are classified as depressed or not before using the data to train algorithms.
Facial expressions and body language
Computer vision has made tremendous progress over the past decade, and deep learning models are now able to recognize facial expressions (smiling, frowning, surprise, etc.) with a high level of accuracy. Such technology is being applied to recognize mental health issues like depression. For example, subjects are being shown emotional images (both positives and negatives) with their reaction being automatically analyzed. It has been shown that depressed subjects present slower reactions to positive visual stimuli, which a neural network could potentially detect.
Speech: One of the most promising avenues
The idea that depression can be recognized through speech is not new. Back in 1921 Emil Kraepalin, often regarded as the founder of modern psychiatry, described depressive voices as follow:
Patients speak in a low voice, slowly, hesitantly, monotonously, sometimes stuttering, whispering, try several times before they bring out a word, become mute in the middle of a sentence.
To understand why depression can affect speech, it is important to have a look at how speech is produced, particularly at the source-filter theory of speech production. According to this model, speech is a combination of a sound source (vocal cords), which is modulated by an acoustic filter (vocal tract). Because of the complexity of the vocal tract, speech is a very sensitive output system: a small change somewhere along the tract could lead to noticeable acoustic changes.
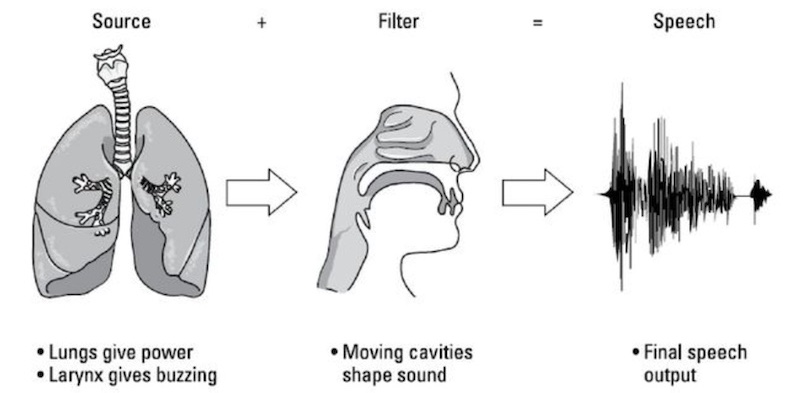
In fact, speech production uses more motor fibers than any other human mechanical activity. Cognitive issues experienced by depressed subjects have been shown to affect working memory, impacting speech planning and neuromuscular coordination processes. Moreover, changes to some parts of the nervous systems and the level of some neurotransmitters can create changes to muscle tensions and control, thus impacting the vocal cords and vocal tract.
How to measure depression from speech
Research has shown strong correlations between many acoustic features and the speaker’s level of depression. Some of the most efficient features yet are called prosodic features, which represent variations in the perceived rhythm, stress, and intonation of speech. Such features have also been shown to work well in similar tasks like emotion recognition.
The field of speech processing, however, (and also deep learning in general) is moving towards the use of raw audio waveforms directly, effectively letting neural networks decide which features are the most efficient for the job. These are exciting times, as new approaches are enabling training on large quantities of unlabeled data, improving many tasks including depression detection.
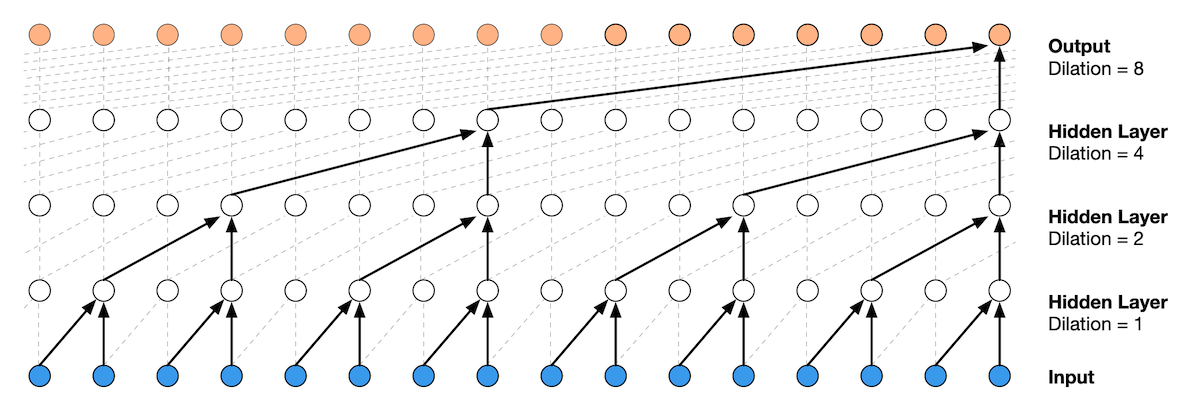
Speech processing is more and more working with raw audio directly as input (here processed by a dilated convolutional neural network). Image credit: Wavenet model from DeepMind
Speech can also be combined with linguistics features for better performance. A first automatic speech recognition model transcribes the audio to text, and a separate model is used to recognize statistical patterns of expressions from the text.
Current state of speech depression detection
In 2016 the Audio-Visual Emotion Challenge organized a competition to detect depression from a dataset of recorded interviews from depressed and healthy individuals. One of the most performant models was able to successfully screen 100% of depressed patients from segments of four seconds of speech (although the precision was only 35%, meaning that 65% of depression predictions were false positive). Two years later, on the same dataset, an MIT research team improved the precision to 71% (recall 83%) by modeling the sequence of questions in the interview as well as combining speech features with linguistic features.
Today, multiple companies claim to detect depression from speech with twice the accuracy of human practicioners, using as little as 20 seconds of voice data. Our team at WonderTech is currently working on pushing the state-of-the-art through new paradigms in machine learning such as transfer learning and self-supervised learning.
The benefits of the speech-based approach
Speech can be measured cheaply and non-intrusively. Every smartphone can be potentially used. Speech can be monitored naturally and there is no need to ask patients to fill a questionnaire or go through complicated EEG testing.
Speech can monitor changes compared to each individual’s own baseline. As speech is so cheap to monitor, it can be done much more often and allow establishing a “normal” baseline personalized to the unique characteristics of the voices of different persons. Detecting deviation from baselines can then be much more informative than tests performed at a single point in time.
Speech can help respect privacy. With the improvement of computation for smartphones and wearables, deep learning models are increasingly moving on-device so that no data is sent to the cloud. Apple for example, just announced at this year’s WWDC that they would be handling requests to Siri directly on the iPhone, preventing any audio to leave the device.
Future challenges
The field is progressing rapidly but some challenges remain:
Small size of datasets. The sensitivity of depression-related data makes it hard to collect a large quantity of high-quality data to train machine learning models. However, progress made in transfer learning and self-supervised learning can help mitigate the issues by making use of generic speech data.
Model biases. For example gender has been shown to have a big influence on models’ predictions. Final solutions also need to function in any kind of environment, and should not be influenced by audio recording conditions.
Privacy. Data should be processed on-device as much as possible and should be anonymized when training. Depression is and will remain a sensitive subject, and everything should be done to protect patient’s data.
Read next
Detecting Emotions from Voice with Very Few Training Data
The Rise of Self-Supervised Learning
Building a Slogan Generator with GPT-2
Footnotes
-
One of the symptoms must be either 1) depressed mood or 2) loss of interest. Moreover, to receive a diagnosis of depression, these symptoms must cause the individual clinically significant distress or impairment in social, occupational, or other important areas of functioning. The symptoms must also not be a result of substance abuse or another medical condition. ↩