Building a Slogan Generator with GPT-2
Note: If you just want to see the results and play with the final model, you can directly go this webpage to experiment with real/imaginary companies yourself. You can also look at the complete code/data on GitHub.
Back when I was working at branding agency RedPeak, we had many discussions with colleagues about what the rise of AI would mean for the future of the creative industry. A recurrent debate was around creativity and if computers would be able to compete with humans at tasks we consider creative: coming up with interesting concepts, designing key visuals, writing good copy…
Currently taking a gap year to experiment with the latest developments in machine learning, I decided to put this idea to the test to see how good machine learning algorithms could be at generating creative copy. Slogans and taglines seemed like a good place to start with as such writing requires good imagination and creativity. The small scale of this generation task (no more than a few words) also makes it easy to experiment with the idea!
GPT-2: A Breakthrough in Language Models
There has been a lot of exciting development in the field of NLP recently. The 2017 paper Attention Is All You Need from the Google Brain team introduced a new neural network architecture for encoder-decoder models based solely on attention. This was a first as attention mechanisms were mostly used on top of other architectures, like recurrent neural networks for example, and not as a stand-alone.
Quickly researchers found out that these attention-based models excelled at language-related tasks. Especially you could train a model over large amounts of text (where it would learn syntax, semantics, and grammatical structure) and then fine-tune it on a particular downstream task: text classification, sentiment analysis, named entity recognition… Over 2018-2019 many new models were introduced which reached state-of-the-art performance for natural language tasks: BERT, XLNet, Roberta…
GPT-2 comes from this recent wave of large models based on attention, and was created by OpenAI’s research team. It made headlines when published, as it was deemed “too dangerous” to be released in its full version. Recently people have been experimenting with it to generate anything from news articles to poetry… Someone even built a complete text-based role playing game with it!
So what is GPT-2?
Essentially, it is a very large language model trained on 40GB of text from the web.
A language model is a model trained to predict the probability distribution of the next “token” considering the preceding tokens that came before it. A token can be a word, a letter, a subpart of a word… It is up to whoever build the model to decide what the tokens will be.
For example, consider the following sequence of word tokens:
[A] [robot] [may] [not] ...
We would expect our model to give high probabilities to words that make sense after “A robot may not”. For example “kill”, “injure”, “attack”… are all likely options.
This is all it does. You give GPT2 a series of tokens, and it outputs the probabilities for what comes next (among all possible tokens in the vocabulary). If you append a token with high probability to the sequence, and then repeat this step again and again you can generate large spans of coherent text.
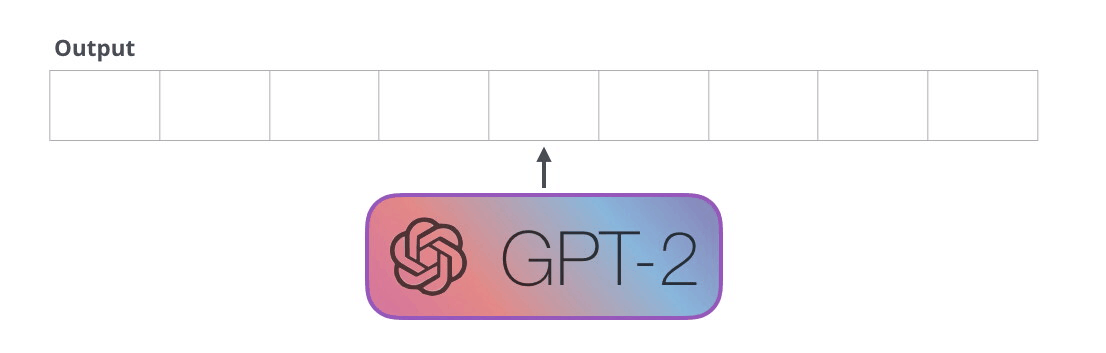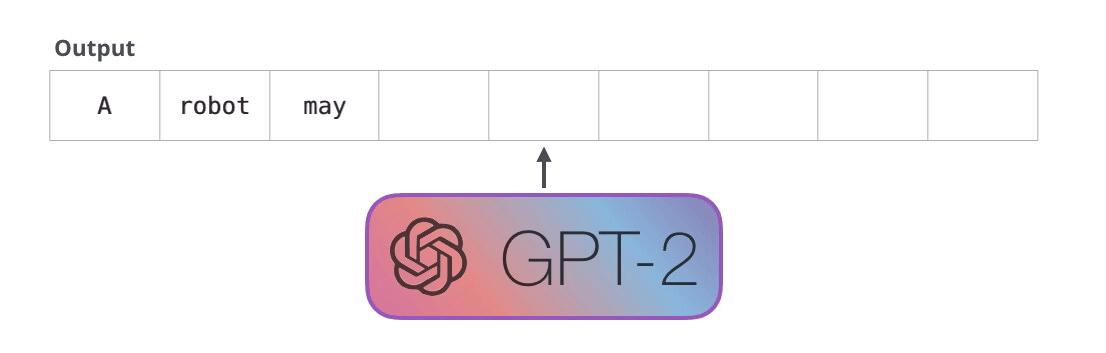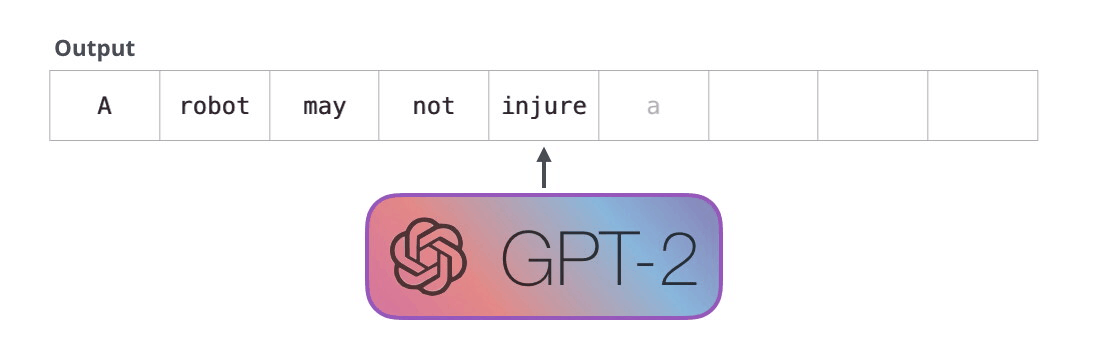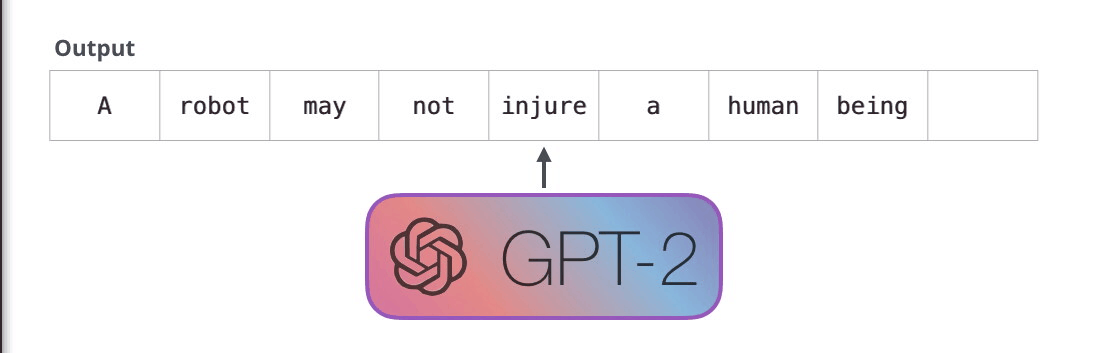
Animation from The Illustrated GPT-2
Let’s now see how we could apply this model to generate creative copy.
Adjusting GPT-2 for Slogan Generation
The model will take as input the name and short description of a company, and then output relevant suggestions of slogans based on its industry, products, or any other element/clue that can be find in the company’s description.
One way to gather the relevant data would be to collect a large quantity of slogans, taglines, or other types of creative copy by just crawling many company websites. We could then match these slogans with company descriptions from Wikipedia or databases like CrunchBase.
However for this experiment I decided to keep things simple. I used the ~10,000 slogans collected by TextArt.ru (thanks to them!) to see if I could obtain interesting results with these.
The data structure is really simple, it is just the “context” (company’s name and description) along with the slogan:
| Context | Slogan |
|---|---|
| Nestle Crunch Stixx, crispy wafer sticks with chocolate | Give your afternoon a lift. |
| White Tiger, organic energy drink | From nature, naturally. |
| L’Oreal Paris Shampoo | Because you’re worth it. |
| … | … |
Examples of slogans from the dataset, you can see the full dataset on GitHub
The Objective Function
Because this is a creative task, the ultimate performance indicator will be human judgement about the coherence, wit, originality of the slogans generated. However we still need a good proxy measure to train our model the right way.
Language models are mostly evaluated using perplexity and cross-entropy which measures how “confident” our model is about its predictions, the lower the better. We only need to keep track of one of these as both measures are related through the following formula:
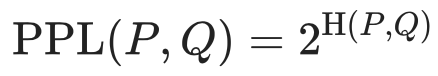
Where H(P,Q) is the cross entropy of our language model’s probability distribution Q relative to the real probability distribution of the language P. For more information on these measures and how they relate to each other I highly suggest this detailed article on The Gradient.
The objective will then be to minimize cross-entropy for our domain-language (the “slogan language”). Yet we don’t want to over-fit to the small dataset of 10K slogans. The model should generalize well to new examples and not merely repeat slogans that it saw in the training set. We want it to be creative and come up with unique and new slogans as often as possible.
Thus the dataset will be split between a train and a validation set to make sure that cross-entropy also diminishes for new examples. We will use early-stopping to interrupt the training when cross-entropy starts to increase on our validation set.
Building the Model with PyTorch and Transformers
Let’s now dive into the code! We will use HuggingFace’s excellent Transformers library to fine-tune GPT2 (with PyTorch). Loading the model is done with only 2 lines of codes:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
model = GPT2LMHeadModel.from_pretrained('distilgpt2')Note that we load a model called “DistilGPT2” here, which is an optimized version of GPT2’s small model trained by the HuggingFace team (you can read their distillation paper for more details). Its performance are slightly lower than the original model but it is also much faster to train and run. This is ideal for the sake of experimenting quickly , but you could also switch to larger versions of GPT2 for better results.
We will need to slightly adjust GPT2 to let it understand context and distinguish between company descriptions (plain text) and slogans (creative copy). Indeed, all the model will see is a sequence of tokens. For example:

Note: The example above shows word-level tokens for simplification, but in practice GPT-2 uses a sub-word tokenization scheme (Byte pair encoding)
In this example, how can the model know which part is about the company context and where the actual slogan begins?
For this purpose, we will introduce two special delimiter tokens to separate between these two kinds of information: <context> and <slogan>. These tokens will be placed before the corresponding sections, hence the example above will become:

There is now more information for the model to distinguish between the two segments. But we can do better and convey even more signal to separate these two: we can apply an extra transformation on our token embeddings to “annotate” tokens from each segment differently.
Here too, the Transformers library makes it easy for us to implement this. When calling the model, we just need to specify the token_type_ids argument with our annotation sequence. In our case this would be:
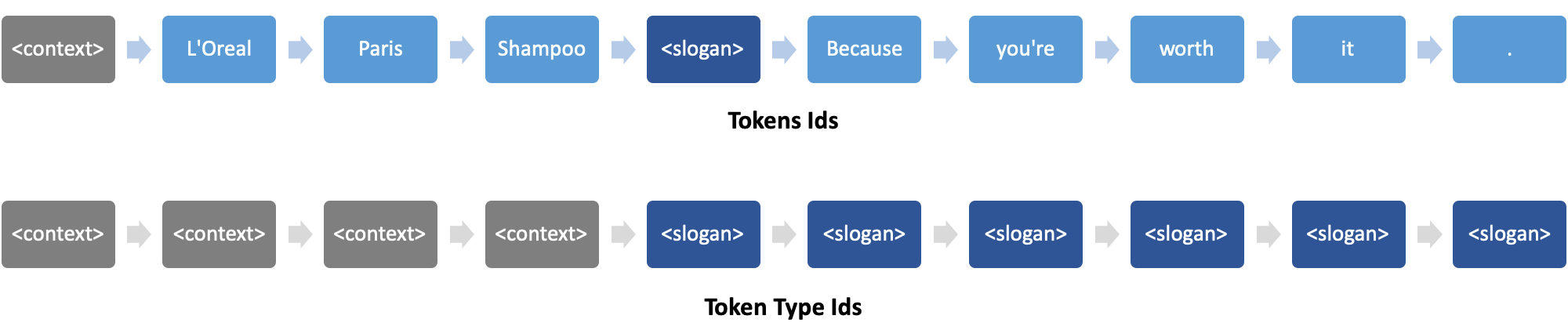
One last detail. GPT2 was pre-trained by OpenAI on large spans of text (1024 tokens) and is not originally made for short sentences like slogans. We will thus need to pad sequences with another special token in order to be able to train with variable-length sequences.
Let’s add these 3 tokens to our tokenizer and model. The HuggingFace’s Transformer library allows us to do that very easily:
SPECIAL_TOKENS_DICT = {
'pad_token': '<pad>',
'additional_special_tokens': ['<context>', '<slogan>'],
}
tokenizer.add_special_tokens(SPECIAL_TOKENS_DICT)
model.resize_token_embeddings(len(tokenizer))Preparing the Data for Training
For each slogan, we will need to create 3 sequences as input for our model:
- The context and the slogan delimitated by
<slogan>and<context>(as described above) - The “token type ids” sequence, annotating each token to the context or slogan segment
- The label tokens, representing the ground truth and used to compute the cost function
As mentioned above, cross-entropy will be the cost function to minimize. However, we do not want to penalize our model for what it is not supposed to predict (the context and the padding tokens), hence we will only compute cross-entropy on the slogan’s tokens. Using the Transformer library, setting label ids to -1 will tag them to be ignored during cross-entropy computation.
We will create our own class to load and preprocess the data from the CSV file, based on PyTorch’s base Dataset class:
import csv, torch
from torch.utils.data import Dataset
class SloganDataset(Dataset):
def __init__(self, filename, tokenizer, seq_length=64):
context_tkn = tokenizer.additional_special_tokens_ids[0]
slogan_tkn = tokenizer.additional_special_tokens_ids[1]
pad_tkn = tokenizer.pad_token_id
eos_tkn = tokenizer.eos_token_id
self.examples = []
with open(filename) as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# Build the context and slogan segments:
context = [context_tkn] + tokenizer.encode(row[0], max_length=seq_length//2-1)
slogan = [slogan_tkn] + tokenizer.encode(row[1], max_length=seq_length//2-2) + [eos_tkn]
# Concatenate the two parts together:
tokens = context + slogan + [pad_tkn] * ( seq_length - len(context) - len(slogan) )
# Annotate each token with its corresponding segment:
segments = [context_tkn] * len(context) + [slogan_tkn] * ( seq_length - len(context) )
# Ignore the context, padding, and <slogan> tokens by setting their labels to -1
labels = [-1] * (len(context)+1) + slogan[1:] + [-1] * ( seq_length - len(context) - len(slogan) )
# Add the preprocessed example to the dataset
self.examples.append((tokens, segments, labels))
def __len__(self):
return len(self.examples)
def __getitem__(self, item):
return torch.tensor(self.examples[item])We can then build the dataset from the CSV file and the tokenizer:
slogan_dataset = SloganDataset('slogans.csv', tokenizer)Then we divide this dataset into 2 DataLoaders for training and validation.
import math, random
from torch.utils.data import DataLoader
from torch.utils.data.sampler import SubsetRandomSampler
# Create data indices for training and validation splits:
indices = list(range(len(slogan_dataset)))
random.seed(42)
random.shuffle(indices)
split = math.floor(0.1 * len(slogan_dataset))
train_indices, val_indices = indices[split:], indices[:split]
# Build the PyTorch data loaders:
train_sampler = SubsetRandomSampler(train_indices)
val_sampler = SubsetRandomSampler(val_indices)
train_loader = DataLoader(slogan_dataset, batch_size=32, sampler=train_sampler)
val_loader = DataLoader(slogan_dataset, batch_size=64, sampler=val_sampler)Note: we can double the batch size for validation since no backprogation is involved (thus it should fit on the GPU’s memory).
Fine-tuning GPT-2 on the Slogans
Now we will need to train our model and keep track of cross-entropy for both the training and validation set. The following is a function that will perform back-propagation and validation for the number of epochs specified.
import numpy as np
from tqdm import tqdm
def fit(model, optimizer, train_dl, val_dl, epochs=1, device=torch.device('cpu')):
for i in range(epochs):
print('\n--- Starting epoch #{} ---'.format(i))
model.train()
# These 2 lists will keep track of the batch losses and batch sizes over one epoch:
losses = []
nums = []
for xb in tqdm(train_dl, desc="Training"):
# Move the batch to the training device:
inputs = xb.to(device)
# Call the model with the token ids, segment ids, and the ground truth (labels)
outputs = model(inputs[:,0,:], token_type_ids=inputs[:,1,:], labels=inputs[:,2,:])
# Add the loss and batch size to the list:
loss = outputs[0]
losses.append(loss.item())
nums.append(len(xb))
loss.backward()
optimizer.step()
model.zero_grad()
# Compute the average cost over one epoch:
train_cost = np.sum(np.multiply(losses, nums)) / sum(nums)
# Now do the same thing for validation:
model.eval()
with torch.no_grad():
losses = []
nums = []
for xb in tqdm(val_dl, desc="Validation"):
inputs = xb.to(device)
outputs = model(inputs[:,0,:], token_type_ids=inputs[:,1,:], labels=inputs[:,2,:])
losses.append(outputs[0].item())
nums.append(len(xb))
val_cost = np.sum(np.multiply(losses, nums)) / sum(nums)
print('\n--- Epoch #{} finished --- Training cost: {} / Validation cost: {}'.format(i, train_cost, val_cost))After experimenting with different settings, I found that training for 2 epochs is the maximum I could do before the model starts to seriously overfit to the training set.
from transformers import AdamW
# Move the model to the GPU:
device = torch.device('cuda')
model.to(device)
# Fine-tune GPT2 for two epochs:
optimizer = AdamW(model.parameters())
fit(model, optimizer, train_loader, val_loader, epochs=2, device=device)Generating New Slogans
Now that we have a language model who speaks like a typical marketer, how do we actually generate full-length slogans based on a given context?
There are multiple methods to generate a sequence of tokens from a language model, including:
- Greedy sampling
- Beam search
- Top-k sampling
- Top-p sampling
Greedy sampling consists of always choosing the token with the highest probability. This leads to very predictable & repetitive results.
Beam search will generate multiple sequences at the same time (how many is defined by its beam width parameter), and will return the sequence whose overall probability is the highest. This means that the algorithm might end up choosing tokens with lower probability at some point in the sequence BUT these will lead to a final sequence of higher probability in the end.
Top-k and Top-p will sample random tokens according to their probabilities given by the model, but the choice will be made only from the top K tokens with highest probabilities in the list, or the top tokens who together represent at least P probability (the sum of their probabilities together is >= P).
Top-k, Top-p, or a combination of the two usually lead to better results for most applications. Here I re-used the convenient sample_sequence function from the Transformers library to easily sample a full sequence with (optionally) Top-k and Top-p. Feel free to experiment with different settings!
context = "Starbucks, coffee chain from Seattle"
context_tkn = tokenizer.additional_special_tokens_ids[0]
slogan_tkn = tokenizer.additional_special_tokens_ids[1]
input_ids = [context_tkn] + tokenizer.encode(context)
segments = [slogan_tkn] * 64
segments[:len(input_ids)] = [context_tkn] * len(input_ids)
input_ids += [slogan_tkn]
# Move the model back to the CPU for inference:
model.to(torch.device('cpu'))
# Generate 20 samples of max length 20
generated = sample_sequence(
model,
length=20,
context=input_ids,
segments_tokens=segments,
num_samples=20,
temperature=1,
top_k=0,
top_p=0.0
)Note the temperature parameter, which is used to divide the probabilities before sampling. A high temperature will “uniformize” the sampling and make the model more creative. A low temperature however will accentuate differences in probabilities and make the model more confident in its choice.
Results and Future Improvements
It’s time to generate some slogans! Here are 10 random examples generated from the context “Starbucks, coffee chain from Seattle” (raw output, not cherry-picked):
Are you a big deal? Recipes choose Starbucks.
Fit for yourself. Have a cup of Starbucks. Have a cup of coffee.
Kick start, start. Loaded fresh.
Sheer coffee with touch.
Starbucks. Everywhere you are.
Starbucks knows its best when it's Starbucks.
Great coffee from our staff.
Starbucks bean clarity since 1996.
Serious coffee should never be given the same.
America's Starbucks moment.
Starbucks. Digest. Locale.
Superior coffee taste, life, and more.
Great coffee comes from country out.
Fine coffee, great coffee, lovely service.
Intaste the bean. Real coffee.
Imagine the difference in Starbucks.
Pick it up!
Time is not enough.
Experience. Enjoy. Pleasure.
Inspiring science.
Some slogans look great and a few are quite creative! However some don’t make sense at all.
What is really interesting is that GPT-2 is able to come up with catchy phrases even if they were not present in the slogan dataset. For example, “Everywhere you are”, ‘Bean clarity’ or ‘Pick it up!’ are nowhere to be found among existing slogans, yet they are quite a good match to the given context.
We would be able to get better results and less nonsense if we could fine-tune GPT2 longer. However the small size of the dataset makes it hard to train further without serious overfitting. It would be interesting to collect more data for this purpose, leveraging creative copy found on company websites for example. Building a bigger dataset would also allow us to use a much larger version of GPT-2, which can greatly improve the quality of the generation!
Any other ideas for improvement? What do you think about using machine learning for creative tasks in general? Please let me know in the comments or by email!
You can find the full code and data on GitHub.