Build a Collaborative Chatbot with Google Sheets and TensorFlow

Currently living in Taiwan, I recently joined the Taiwan Bot 🤖 project along with Shawn and Eric. The idea is to build a go-to assistant to help foreigners answer their questions about moving to, working, and living in Taiwan (pro-tip: ask the bot where to find cheese or chocolate).
Building a functional and useful chatbot is a non-trivial project. Fortunately, there has been impressive progress in the fields of machine learning and natural language processing (NLP) in the past few years. Moreover, the democratization and open-source sharing of cutting-edge deep learning models from research work at large tech companies like Google or Facebook is making it possible for anyone to implement the latest state-of-the-art solutions.
The Universal Sentence Encoder, recently released by Google AI, is one of these new models available via Tensorflow Hub. Trained in a multi-tasking fashion, the model can encode sentences into meaningful continuous representations that work well on a range of different tasks. It is thus ideal for transfer learning and performs competitively with more complex models like BERT. Moreover, it can run much faster than BERT or other similar Transformer models and is thus more applicable to real-world problems. There is even a Lite version of the model, small enough to run in Javascript on the client-side.
The project
Despite being an amazing place to live, Taiwan is still misunderstood by most foreigners. We think that a fun and approachable chatbot could help people understand a lot more about all the great things this place has to offer, as well as answer most of the questions they might have about living here.
We decided to start with a limited scope first and to focus on answering practical questions about moving to and living in Taiwan. Specifically, we chose to focus on visa issues and the recently created Gold Card program. We plan to expand the bot capabilities in future versions.
When it comes to chatbots, there are a lot of ways to go, and many tools and libraries out there to help you make your plan a reality. However, being just a small team of 3 doing this in our spare time, we didn’t have enough resources and time to build something very sophisticated. We also didn’t want to spend a lot of time to compile a large training dataset. So we looked for the best way to build a system that would be:
- 🧩 Easy and quick to build
- ⚡️ Lightweight and runnable on a small server
- 🔧 Iterable and easy to improve
- 🧠 Focused on finding relevant answers
We chose to build our bot with Microsoft’s Bot Framework SDK for easy development, user management and to be able to easily publish it to multiple platforms like Messenger or Line, the most popular messaging platform in Taiwan. The only thing remaining was to build the brain behind the messages.
Understanding the meaning behind a question
The main challenge when building a bot is relevancy, and this starts by having a clear understanding of what the user’s intention is. There are many approaches possible to make sense of what the user wants. At the most simple, one could simply look for some keywords such as hello, restaurant, or visa. However, this doesn’t take at all into account all the nuances of the language.
We didn’t have the resources to build a full-scale bot that could recognize the user intention among thousands of possibilities, yet we wanted to create something that could be relevant enough so that people would find it useful. So we needed to find an ideal middle ground between complexity and performance.
One of the most important concepts in NLP is one of distributed representations, inspired by the linguistic field of distributional semantics. The core idea is to encode linguistic items (words, sentences) into embeddings (vectors in a large dimensional space) such that items with similar properties should be closer in the resulting space.
You shall know a word by the company it keeps.
- John Rupert Firth (1957)
For example, similar words will cluster together in the vector space:
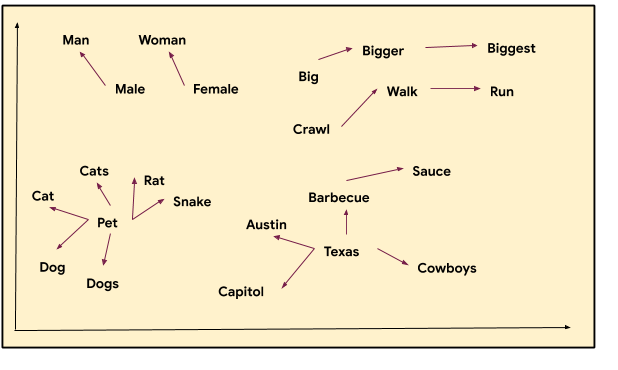
Image from TensorFlow Blog
You could do the same as the above but with sentences, effectively encoding them into large vectors which can be compared between themselves using similarity functions. Hence sentences with similar vector representations are sentences with similar meaning, topic, syntax…
Encoding questions with the Universal Sentence Encoder
The Universal Sentence Encoder is a powerful Transformer model (in its large version) allowing to extract embeddings directly from sentences instead of from individual words. It already powers some impressive Google projects such as Talk to Books or Mystery of the Three Bots.
For our chatbot project, we are first using the model to encode all the questions that we think users would want to ask to the bot. This can be done in a few lines of code thanks to the convenient TensorFlow Hub library:
import tensorflow as tf
import tensorflow_hub as tfhub
model = tfhub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
questions = [ ... ] # questions most likely to be asked to the bot
answers = [ .... ] # all answers to the questions above
batch_size = 10
embeddings = []
for i in range(0, len(questions), batch_size):
embeddings.append(model(questions[i:i+batch_size]))
questions_embeddings = tf.concat(embeddings, axis=0)
Then whenever a user asks a question, we can just extract its embedding and find the most similar question in our database of embeddings. In our case we use a simple vector dot product as a similary function:
def find_best_answer(question: str) -> str:
embedding = model([question,])
# compute dot product with each question:
scores = questions_embeddings @ tf.transpose(embedding)
return answers[np.argmax(tf.squeeze(scores).numpy())]
Google Sheets as a collaborative database
We built our dataset using a simple Google spreadsheet with 2 columns: questions and answers. Whenever a user asks a question, we just find the most relevant question and return the appropriate answer.
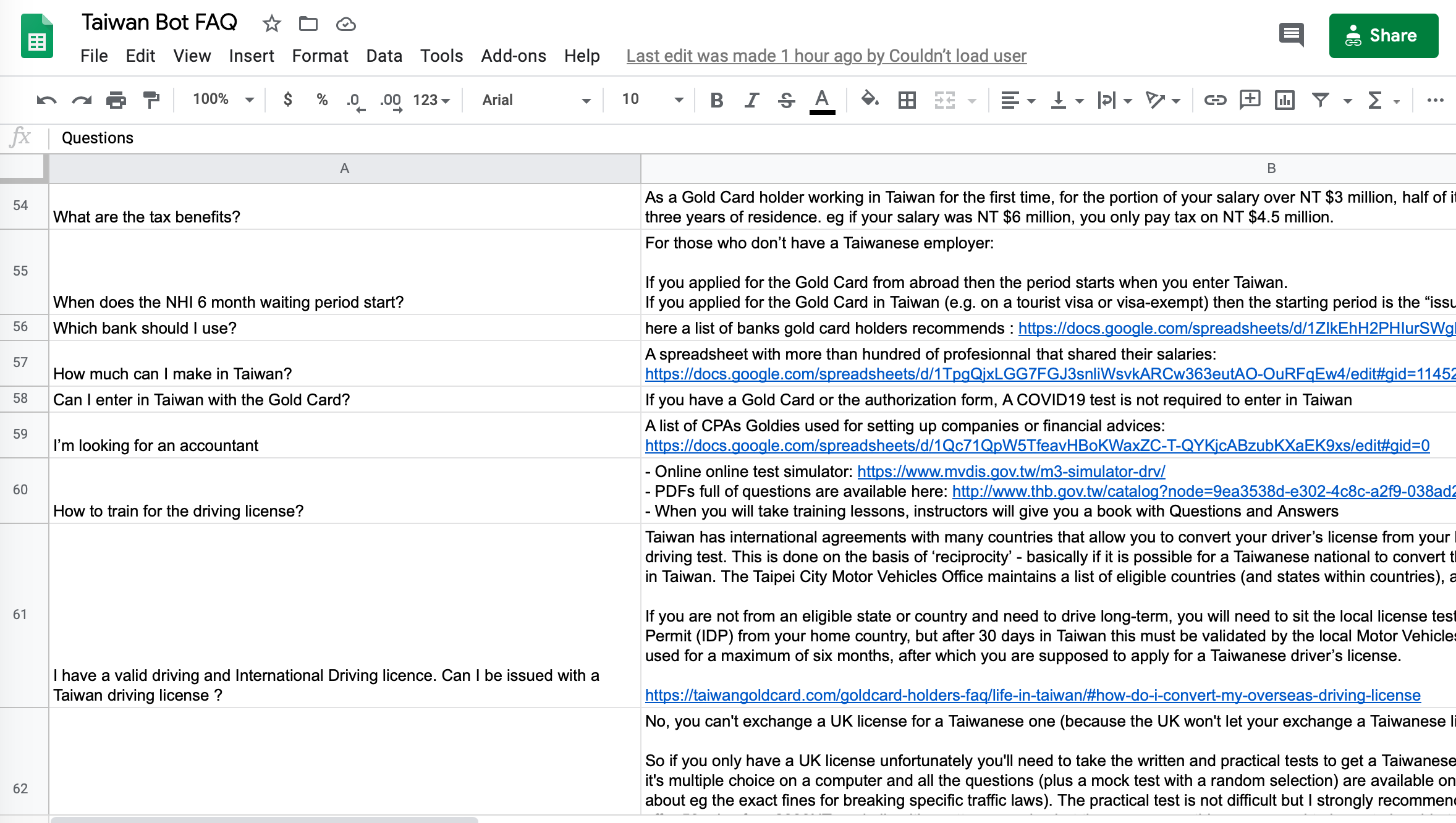
This approach, while relatively simple, is a flexible enough for efficiently working together. Querying the data is done once during startup with a few lines of code:
client = gspread.authorize(
ServiceAccountCredentials.from_json_keyfile_dict(SERVICE_ACCOUNT_INFO_DICT,
['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'])
)
sheet = client.open(SPREADSHEET_FAQ_FILE).worksheet(SPREADSHEET_SHEET_NAME)
questions = list(map(str.strip, sheet.col_values(1)[1:]))
answers = list(map(str.strip, sheet.col_values(2)[1:]))
Here is an example of a conversation with the bot:
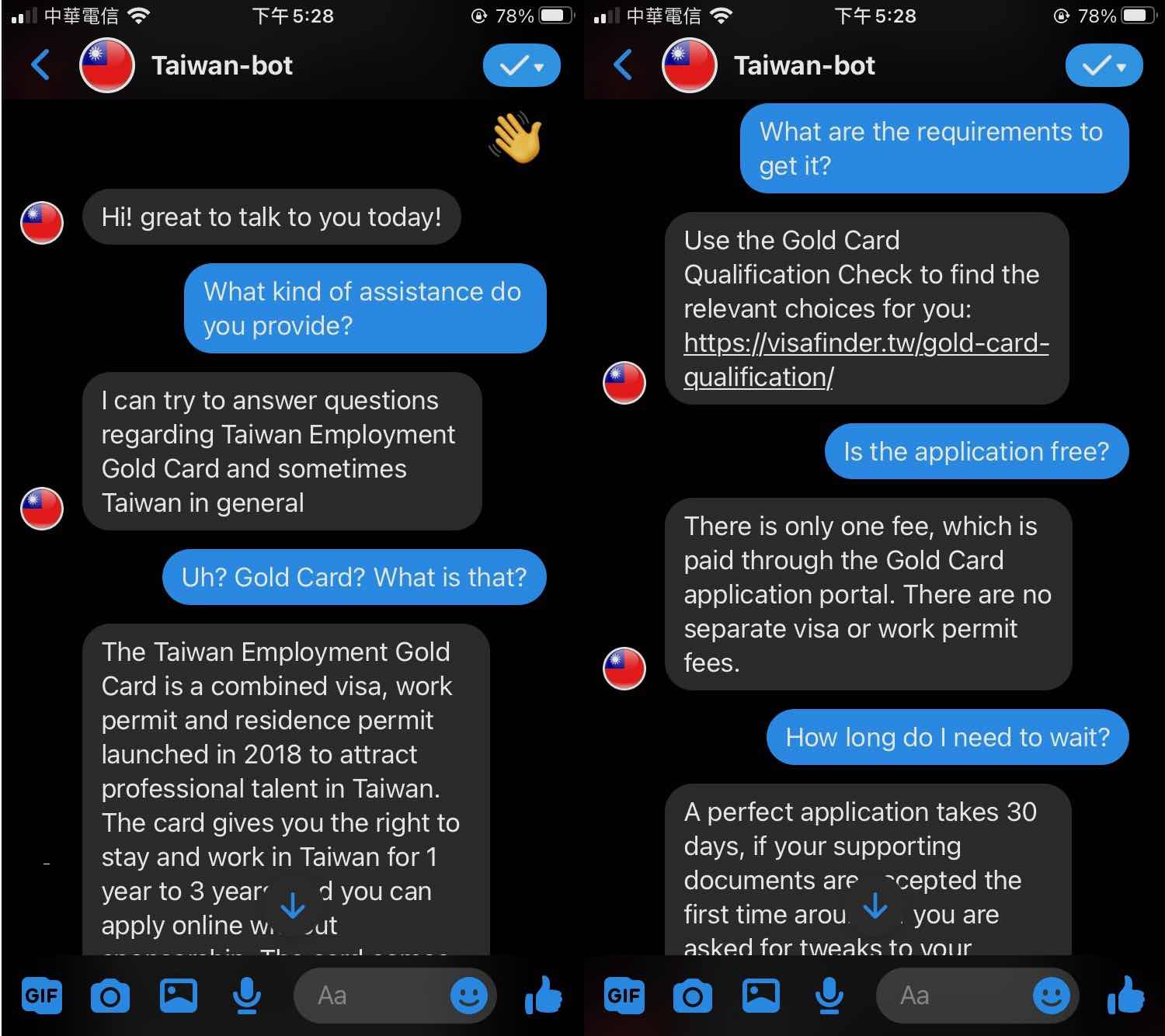
Continuous improvement
We did our best to think about what would be the most commonly asked questions but, of course, we cannot predict everything people will ask. This is why if you ask a question that is not present in our database, the bot can answer with something completely unrelated. To prevent this, we built a small logging system to be able to track the questions asked to the bot and which question it thought was the most similar (along with the similarity score).
For example, here is what happened behind the scenes during the small conversation above. The first column is the user message. The second column is the most similar question (as based on the embeddings similarity). The third column is the best answer and the last column the computed similarity score. If the similarity score is not good enough, the bot will answer with a generic reply ” Sorry, I cannot help with that yet “.

This logging system will also help us improve our answers as more people use the bot and new edge cases are found. Still, no chatbot is perfect, and we think the bot will be most useful in a context where humans can take over when the bot fails. For example, on Slack, we added the bot to a general FAQ channel where people can get assistance from both the bot and humans for more specific information.
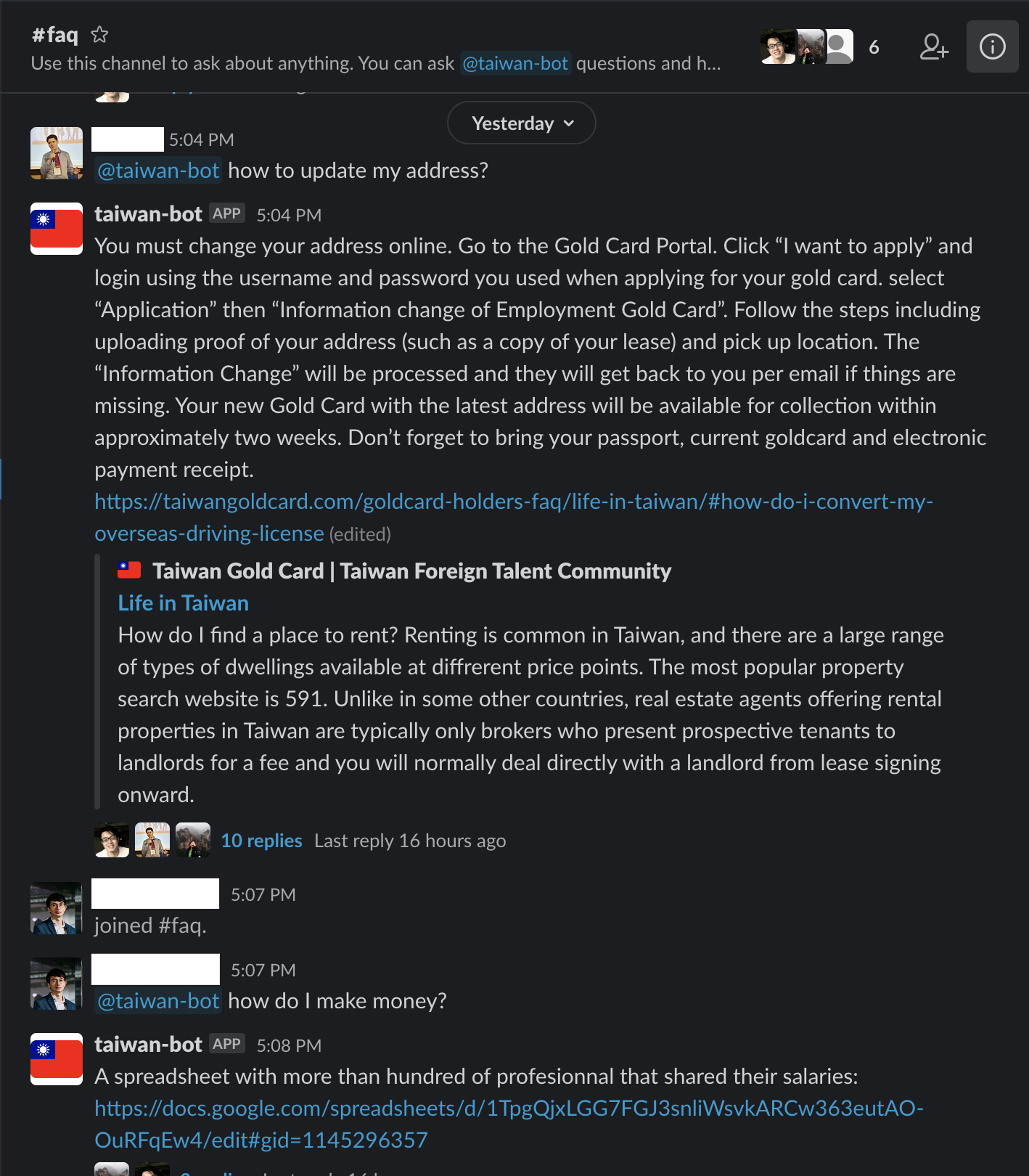
Conclusion
Building an effective chatbot doesn’t have to be a complex project. As long as the scope is relatively narrow, it is possible to use a general encoder model like the Universal Sentence Encoder to build something useful. The hard part is collecting enough questions/answers for the bot to be able to answer most questions. It is also important to regularly monitor what users are asking and complement new data whenever the bot can’t find a relevant answer.
If you are also living or considering to move to Taiwan, you can chat with Taiwan bot on Messenger here!
Read next
Unleash GPT-2 (and GPT-3) Creativity through Decoding Strategies